- Test methodology
- Test summary
- Postgres only performance
- Kafka + Postgres performance
- Cassandra + Kafka + Postgres performance
- Disk usage
- Thank you
ThingsBoard has been run in production by numerous companies in both monolithic and microservices deployment modes. This article describes the performance of a single ThingsBoard server in the most popular usage scenarios. It is helpful to understand how ThingsBoard scales vertically (monolith) before describing how it scales horizontally (cluster mode).
Test methodology
For simplicity, we have deployed a single ThingsBoard instance with all related third-party components in a docker-compose environment on a single EC2 instance. The test agent provisions and connects a configurable number of device emulators that constantly publish time-series data over MQTT.
Various IoT device profiles differ based on the number of messages they produce and the size of each message. We have emulated smart-meter devices that send messages as a JSON with three data points: pulse counter, leakage flag, and battery level. Each device used a separate MQTT connection to the server.
ThingsBoard stored all the time-series data in the database. ThingsBoard also processed the data using the alarm rules to create alarms if the battery level is low. We have scaled the test from 5K to 100K devices and message rate from 1K msg/second to 10K messages per second. Our team executed the tests for at least 24 hours to ensure no resource leakage or performance degradation over time. We have also included instructions to replicate the tests. Links to the instructions are in the details of each test run.
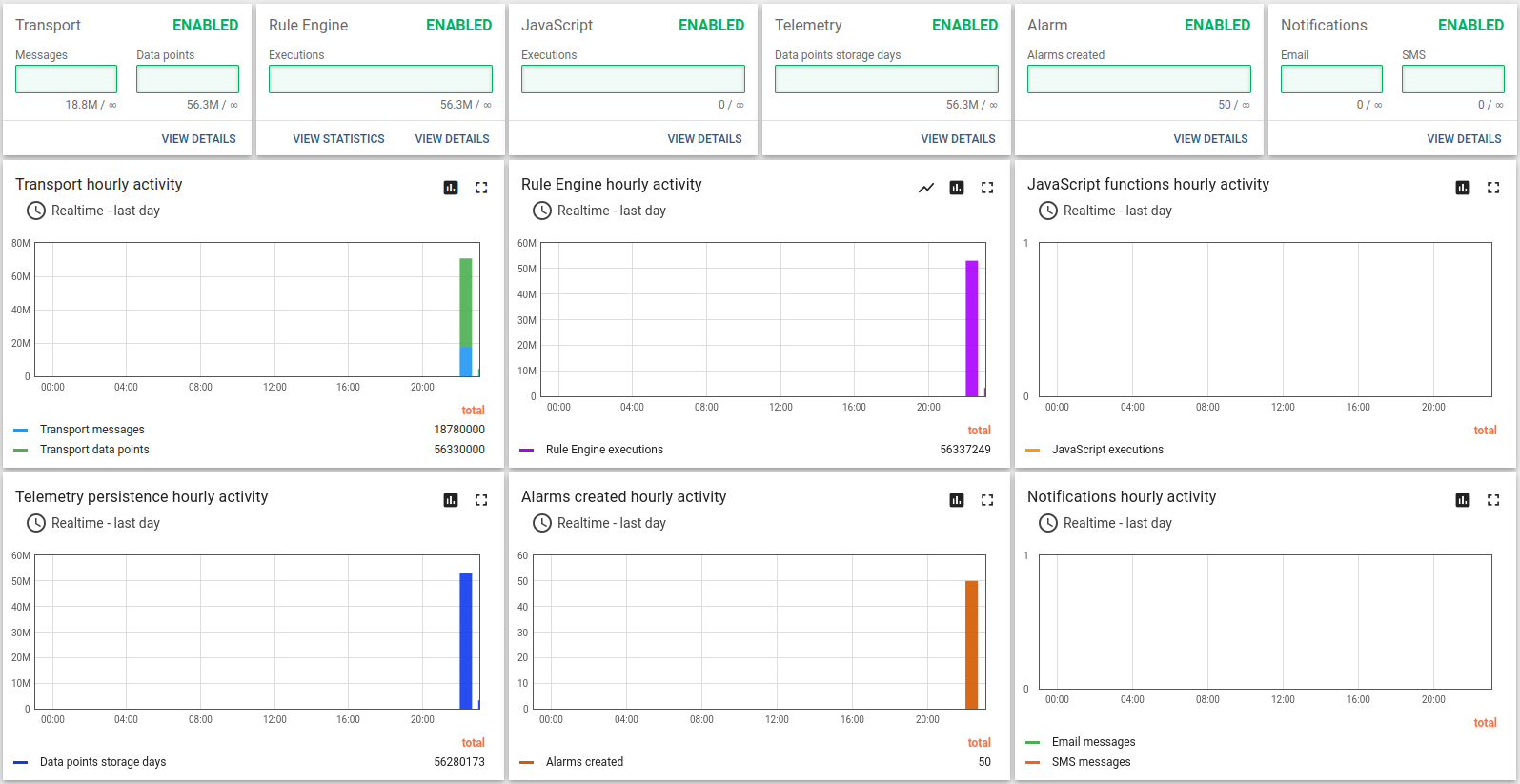
Additional tool set we use for our tests: Postgres, Java and ThingsBoard used to visualize the performance.
As an output we will analyse the ThingsBoard rule engine statistics dashboard and fancy API usage stats.
Note: Each IoT use case is different and may impact the performance numbers. The tests cover the main functionality of data ingestion and alarm generation.
Test summary
The test scenarios differ in the number of connected devices, messages per second, server type and database used to store time-series data.
| Scenario | Devices | Data points per second | Instance Type | Queue type | Database | CPU Usage | Write IOPS |
|---|---|---|---|---|---|---|---|
| Scenario A | 5K | 1K | t3.medium: 2 burstable vCPU, 4GB RAM | in-memory | PostgreSQL | 27% | 800 |
| Scenario B | 5K | 15K | m6a.large: 2 vCPU, 8GB RAM | Kafka | PostgreSQL | 95% | 850 |
| Scenario C | 25K | 30K | m6a.2xlarge: 8 vCPU, 32GB RAM | Kafka | PostgreSQL + Cassandra | 75% | 200 |
| Scenario D | 100K | 15K | m6a.2xlarge: 8 vCPU, 32GB RAM | Kafka | PostgreSQL + Cassandra | 71% | 700 |
| Scenario E | 100K | 30K | m6a.2xlarge: 8 vCPU, 32GB RAM | Kafka | PostgreSQL + Cassandra | 95% | 240 |
Postgres only performance
Scenario A
Load configuration:
- 5000 devices;
- 1000 msg/sec over MQTT, each mqtt message contains 3 data points resulting in 3000 data points/sec;
- PostgreSQL Database;
- In-memory queue.
Instance: AWS t3.medium (2 vCPUs Intel, 4 GiB, EBS GP3)
Estimated cost: 19$ EC2 + x$ CPU burst + 8$ EBS GP3 100GB = 30$/mo
Statistics related to the test execution on x64 architecture:
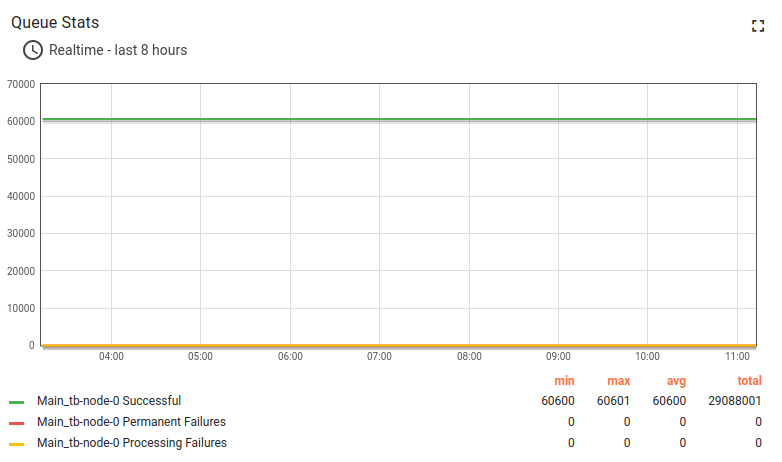
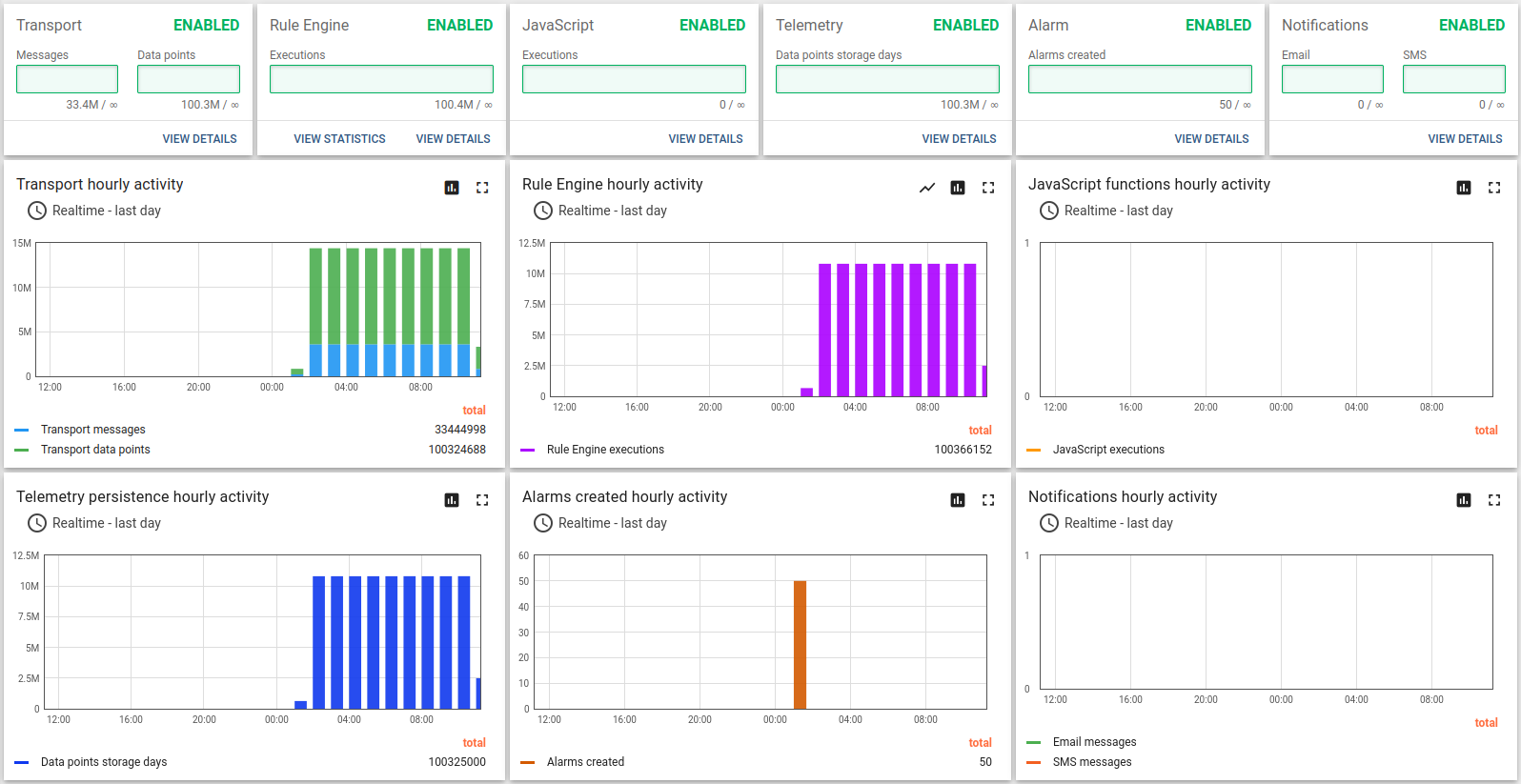
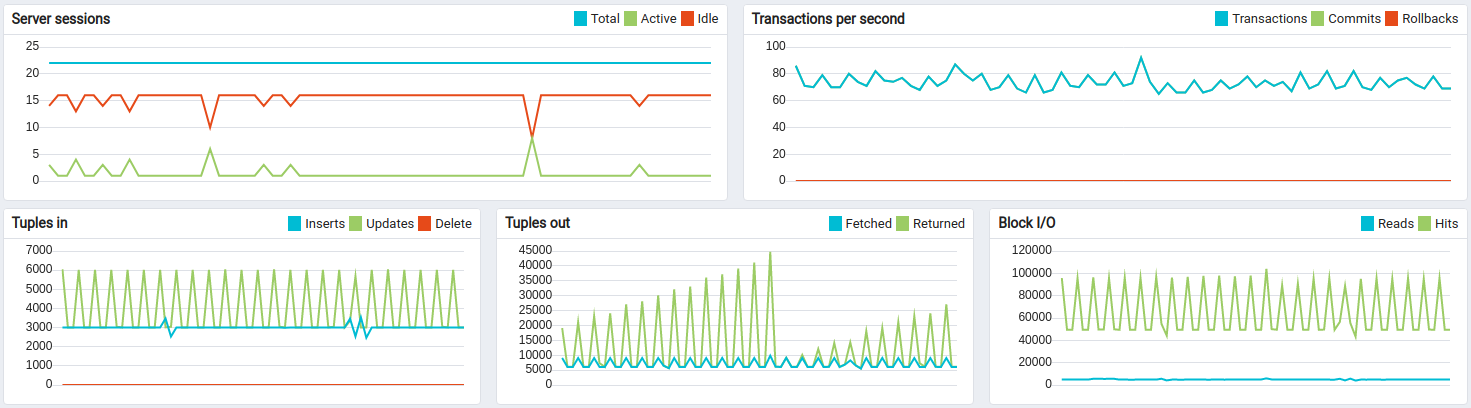
Statistics related to the test execution on ARM architecture (t4g.medium):
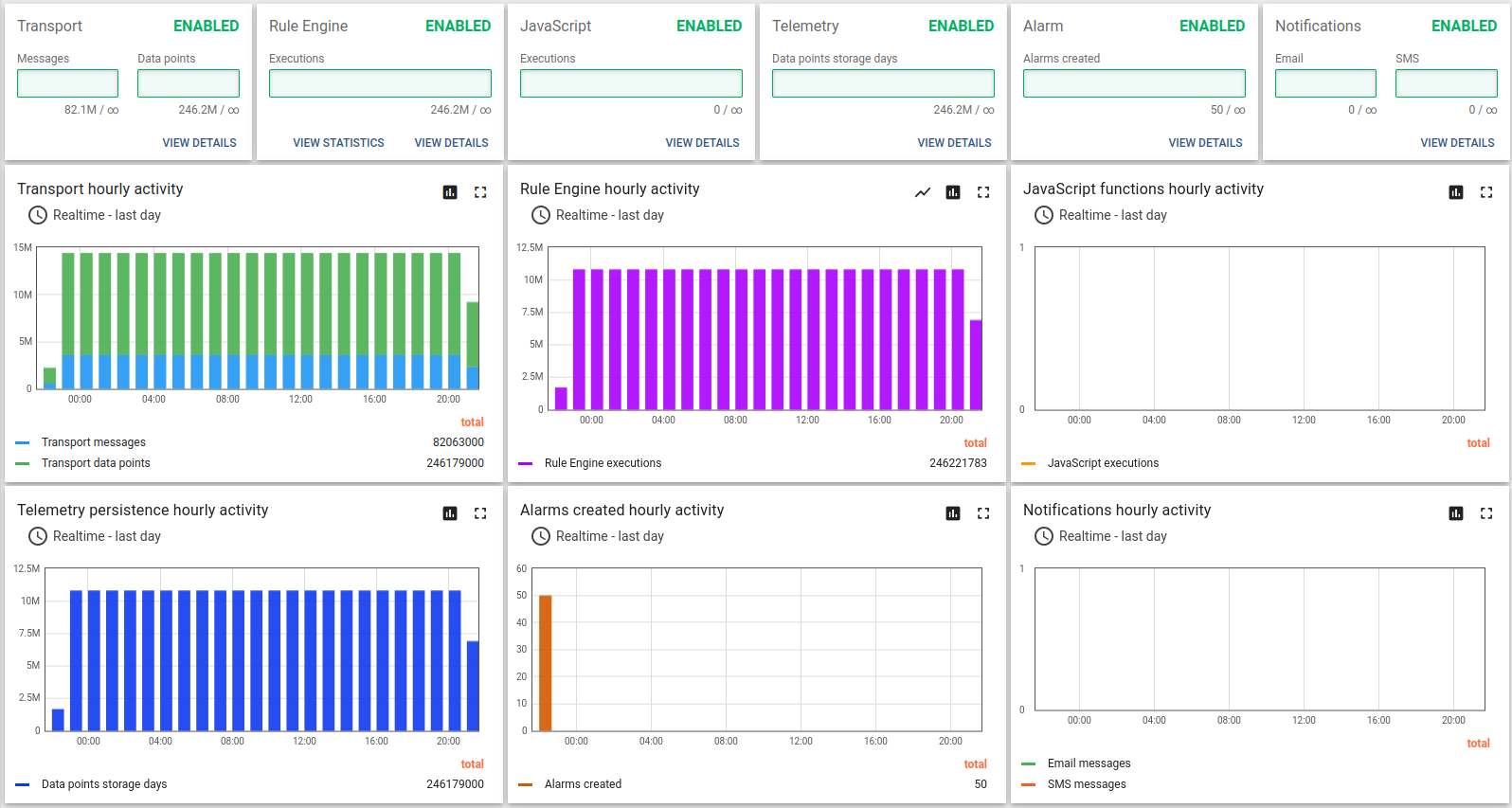
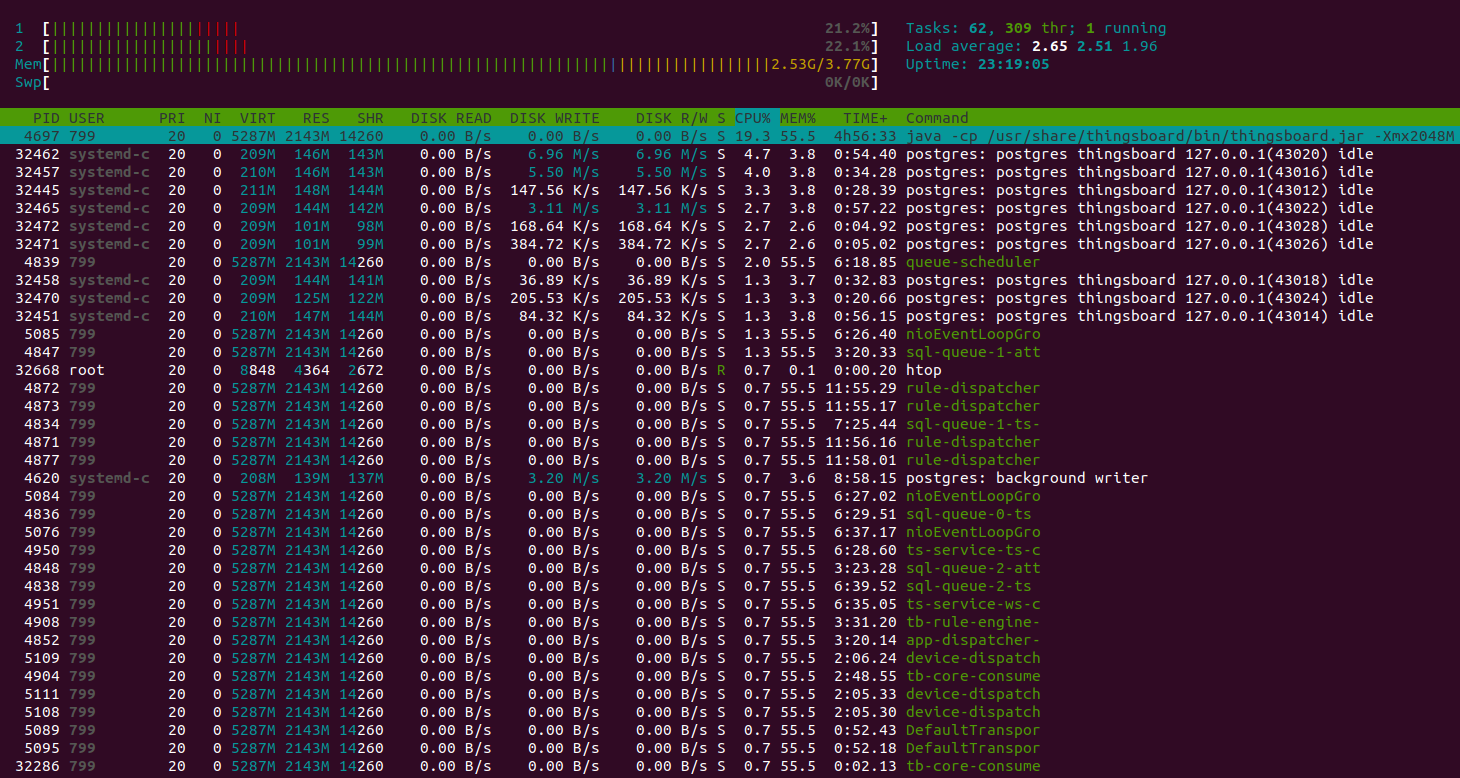
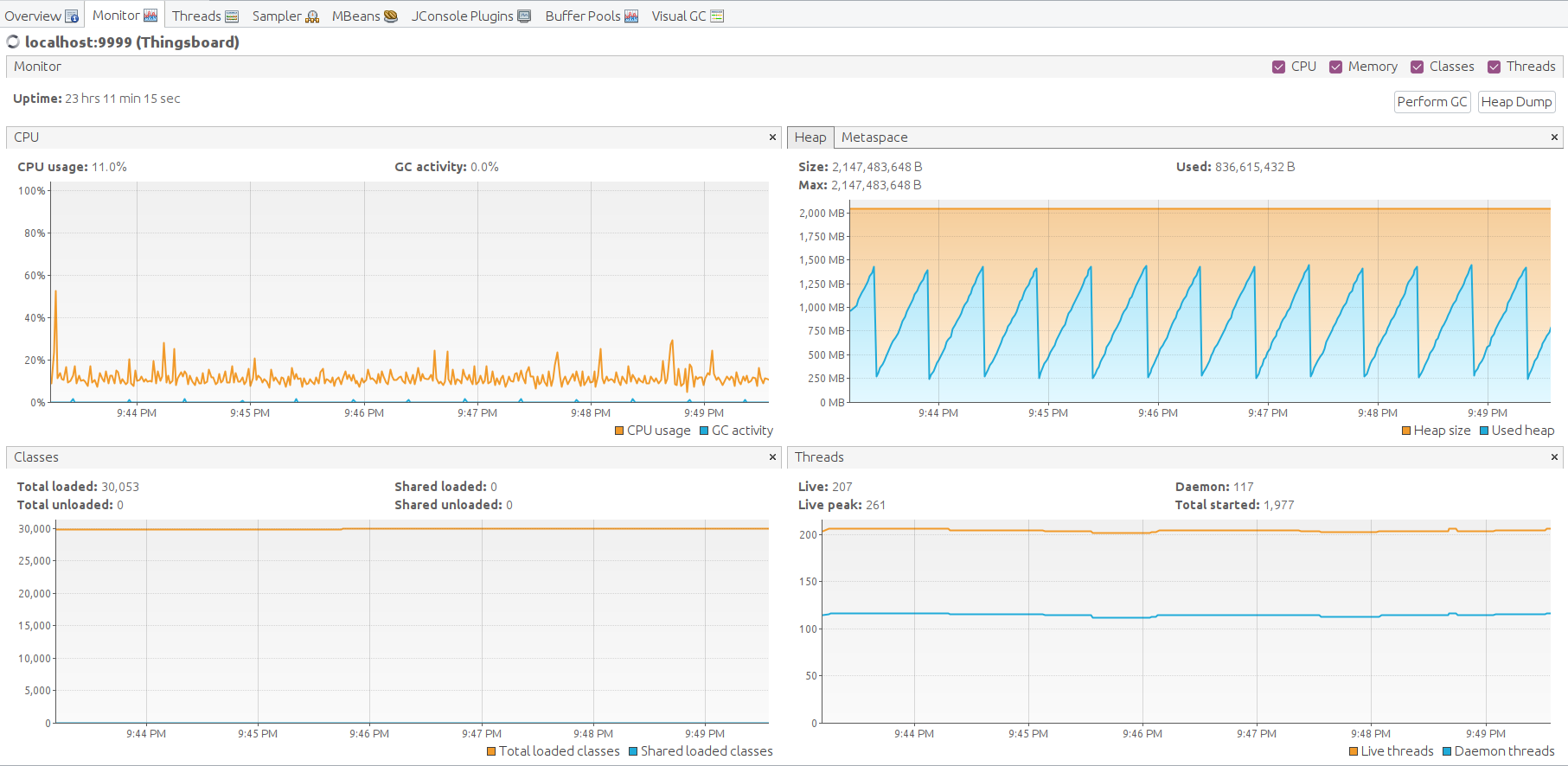
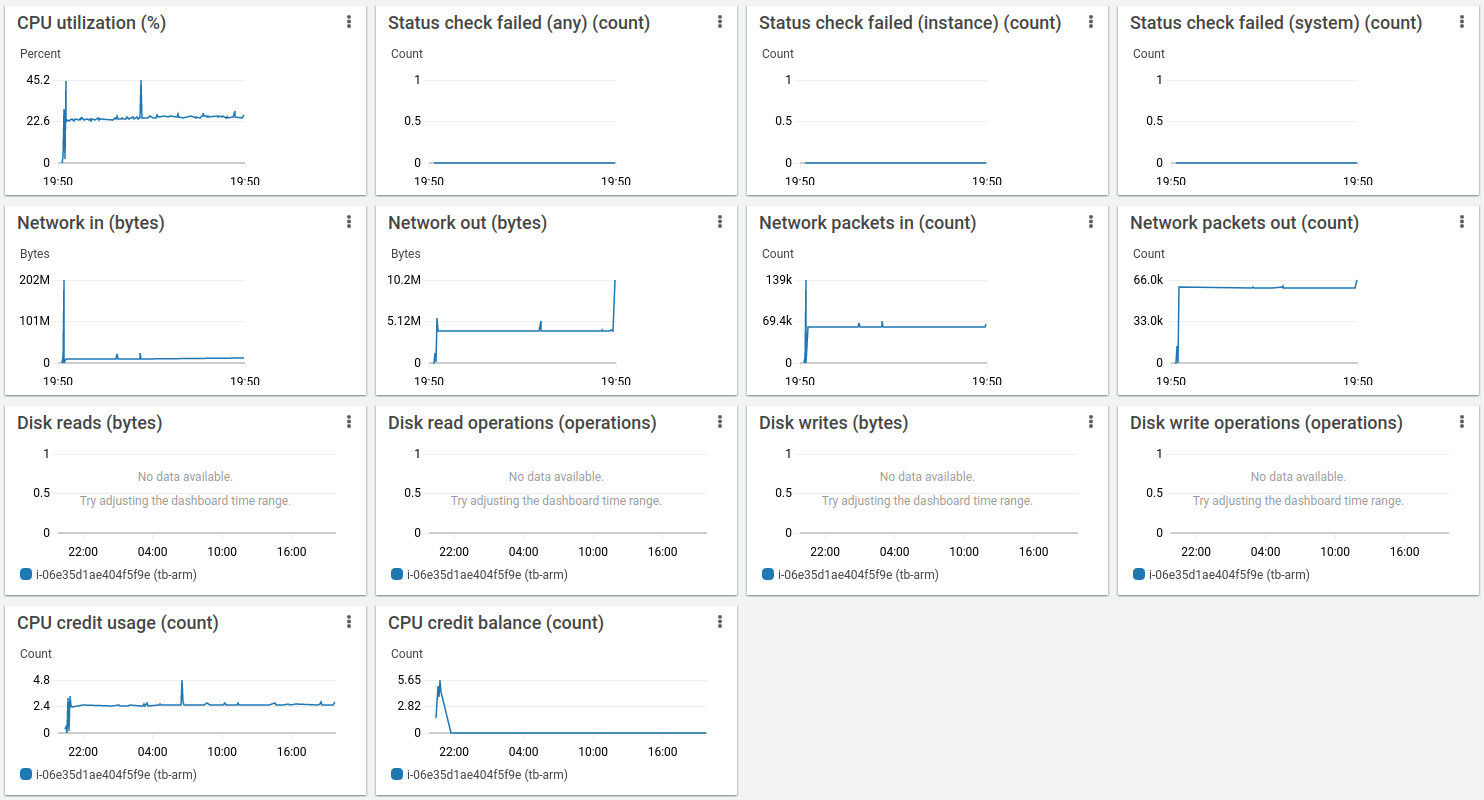
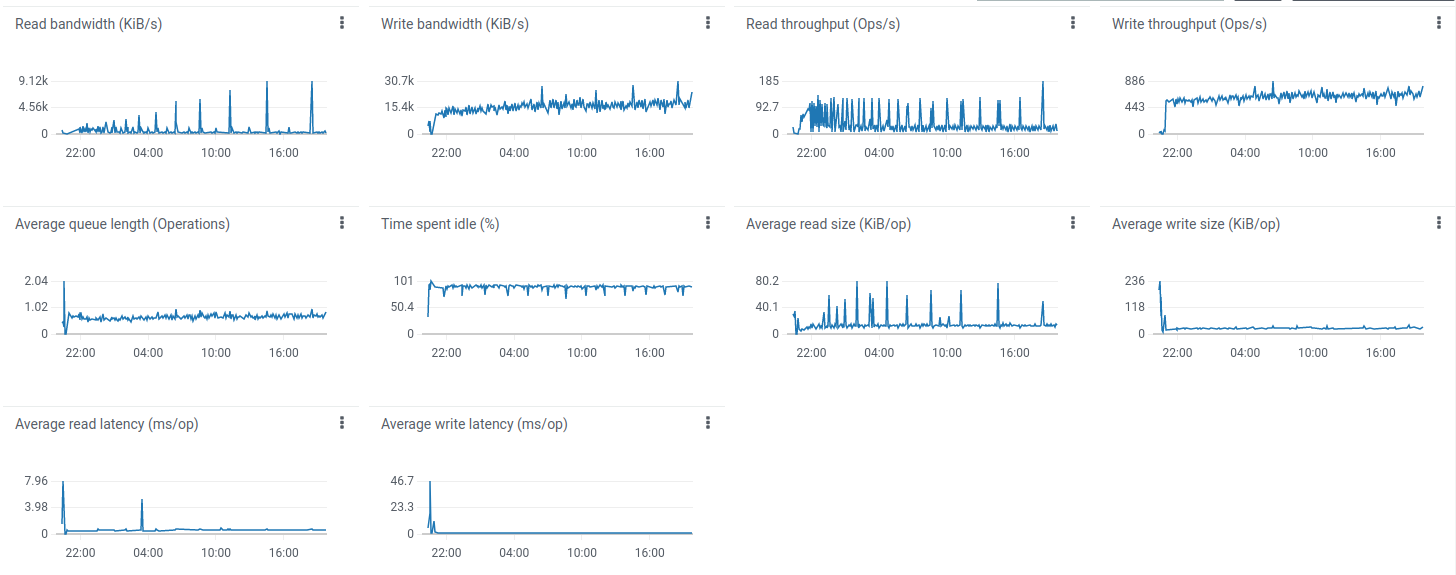
Lessons learned
This setup is mostly for the development environments, due to the in-memory queue.
System can survive and run stable with an up to x3 message rate (3000 msg/sec).
Cloud provider will charge you against CPU burst, but the production will up and running fine.
Note: t3.medium is a burstable instance with a base level performance 20% of CPU load. When you idle, unused CPU time accumulated up to max limit. So please, design your instance to use below 20% in average.
Tip: Enable Unlimited mode in credit specification to get a good performance at first steps
And survive extra load above the limit (additional charges may apply). Without unlimited mode at the first start you have 0 credits to burst CPU up and the system is throttled down to baseline 20% CPU. That will cause the first setup is quite slow without “unlimited mode”.
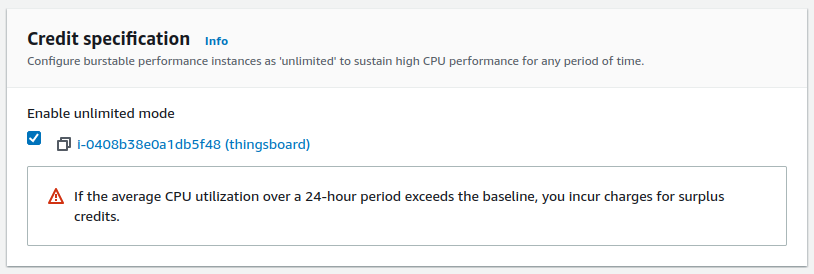
How to reproduce the test:
Setup the ThingsBoard instance on AWS EC2
Use the Docker Compose file listed below to setup the AWS EC2 instance based on the instruction.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
version: '3.0'
services:
postgres:
image: "postgres:14"
network_mode: "host"
restart: "always"
volumes:
- postgres:/var/lib/postgresql/data
environment:
POSTGRES_DB: "thingsboard"
POSTGRES_PASSWORD: "postgres"
tb:
depends_on:
- postgres
image: "thingsboard/tb"
network_mode: "host"
restart: "always"
volumes:
- thingsboard-data:/data
- thingsboard-logs:/var/log/thingsboard
environment:
DATABASE_TS_TYPE: "sql"
TB_QUEUE_TYPE: "in-memory"
TB_SERVICE_ID: "tb-node-0"
HTTP_BIND_PORT: "8080"
TB_QUEUE_RE_MAIN_PACK_PROCESSING_TIMEOUT_MS: "30000"
TB_QUEUE_RE_MAIN_CONSUMER_PER_PARTITION: "false"
# Postgres connection
SPRING_DATASOURCE_URL: "jdbc:postgresql://localhost:5432/thingsboard"
SPRING_DATASOURCE_USERNAME: "postgres"
SPRING_DATASOURCE_PASSWORD: "postgres"
# Java options for 4G instance and JMX enabled
JAVA_OPTS: " -Xmx2048M -Xms2048M -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.rmi.port=9999 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
volumes: # to persist data between container restarts or being recreated
postgres:
thingsboard-data:
thingsboard-logs:
Launch performance test tool
Use the Docker command listed below to launch the performance test tool based on the instruction.
1
2
3
4
5
6
7
8
9
10
11
# Put your ThingsBoard private IP address here, assuming both ThingsBoard and performance tests EC2 instances are in same VPC.
export TB_INTERNAL_IP=172.31.16.229
docker run -it --rm --network host --name tb-perf-test \
--env REST_URL=http://$TB_INTERNAL_IP:8080 \
--env MQTT_HOST=$TB_INTERNAL_IP \
--env DEVICE_END_IDX=5000 \
--env MESSAGES_PER_SECOND=1000 \
--env ALARMS_PER_SECOND=10 \
--env DURATION_IN_SECONDS=86400 \
--env DEVICE_CREATE_ON_START=true \
thingsboard/tb-ce-performance-test:3.3.3
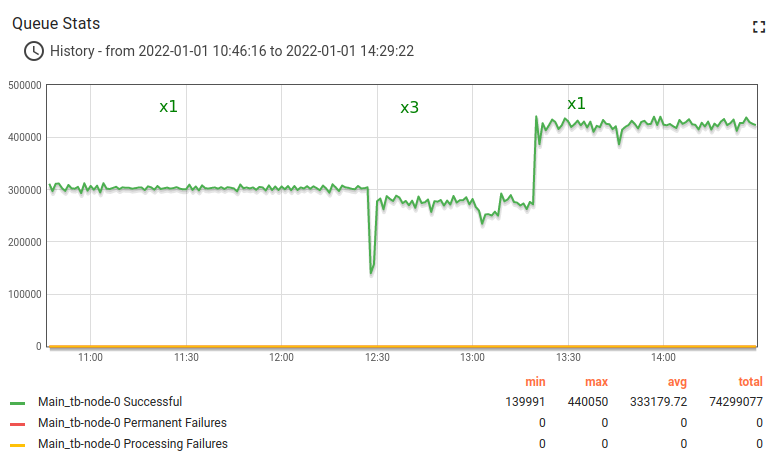
x3 peak load survival
Load configuration:
- 5000 devices;
- 3333 msg/sec over MQTT, each mqtt message contains 3 data points resulting in 10000 data points/sec;
- PostgreSQL Database;
- In-memory queue.
- AWS t3.medium (2 vCPUs Intel, 4 GiB, EBS GP3)
Instance: AWS t3.medium (2 vCPUs Intel, 4 GiB, EBS GP3)
Estimated cost: 19$ EC2 + x$ CPU burst + 8$ EBS GP3 100GB = 30$/mo
Previous section demonstrates successful ThingsBoard deployment designed up to 3000 data points/sec.
Looks perfect, but what happen when we face a peak load on production? Should we worry about?
The cost of failure may be money loss, reputation or carries issue.
The benefits of reliable design may bring you to a better life, no stress, success and constant growing.
Let’s try to handle a messages flood about x3 of regular rate up to 10000 data point/sec.
ThingsBoard docker compose with no change with the previous section. Message rate have been increased gradually.
Performance test was stopped and run with a greater numbers step by step
Use the Docker command listed below to launch the performance test tool based on the instruction.
1
2
3
4
5
6
7
8
9
10
11
# Put your ThingsBoard private IP address here, assuming both ThingsBoard and performance tests EC2 instances are in same VPC.
export TB_INTERNAL_IP=172.31.16.229
docker run -it --rm --network host --name tb-perf-test \
--env REST_URL=http://$TB_INTERNAL_IP:8080 \
--env MQTT_HOST=$TB_INTERNAL_IP \
--env DEVICE_END_IDX=5000 \
--env MESSAGES_PER_SECOND=3333 \
--env ALARMS_PER_SECOND=10 \
--env DURATION_IN_SECONDS=86400 \
--env DEVICE_CREATE_ON_START=false \
thingsboard/tb-ce-performance-test:3.3.3
Test have been passed successfully. Here some great shots.
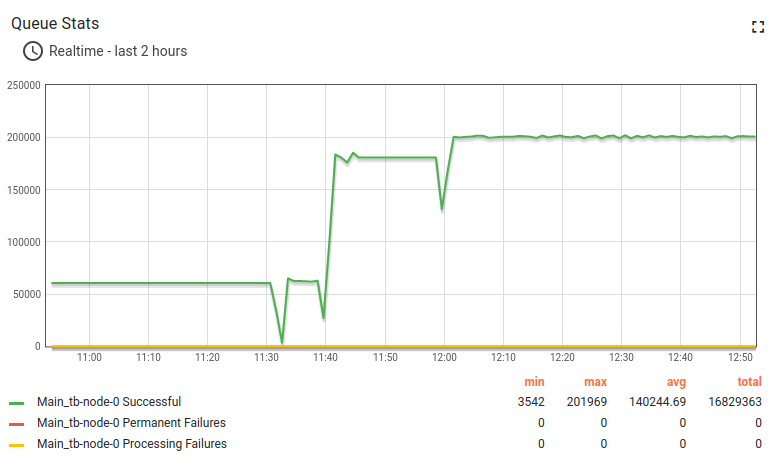
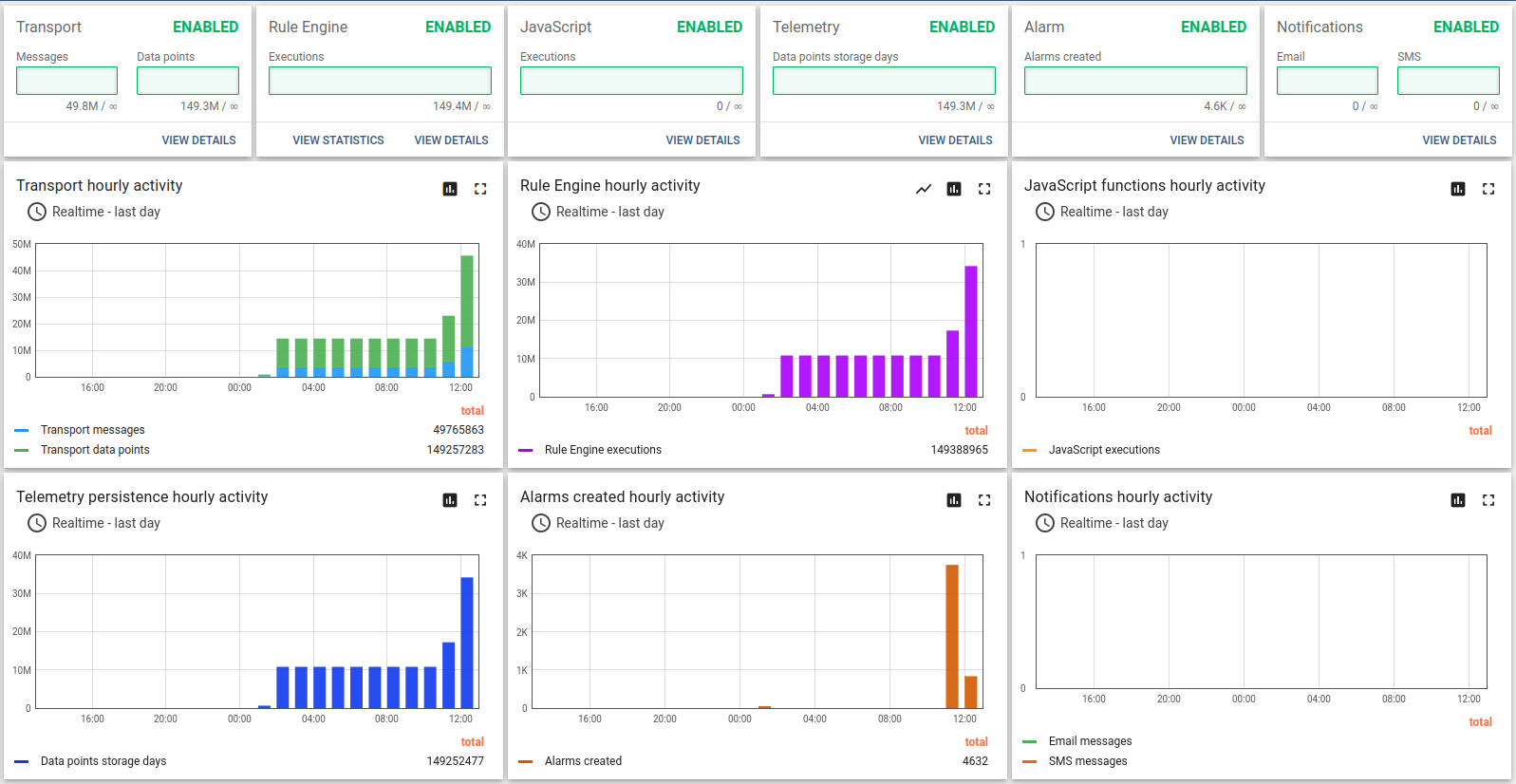
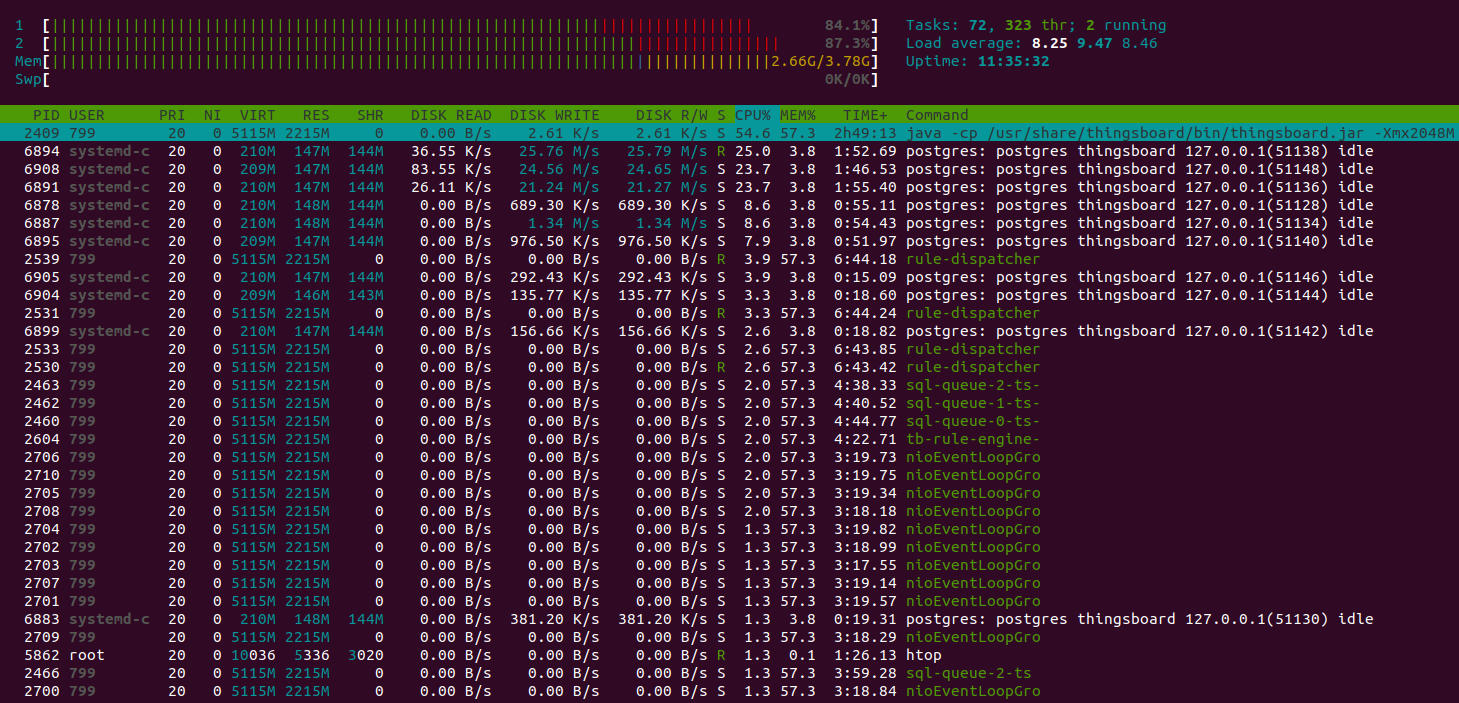
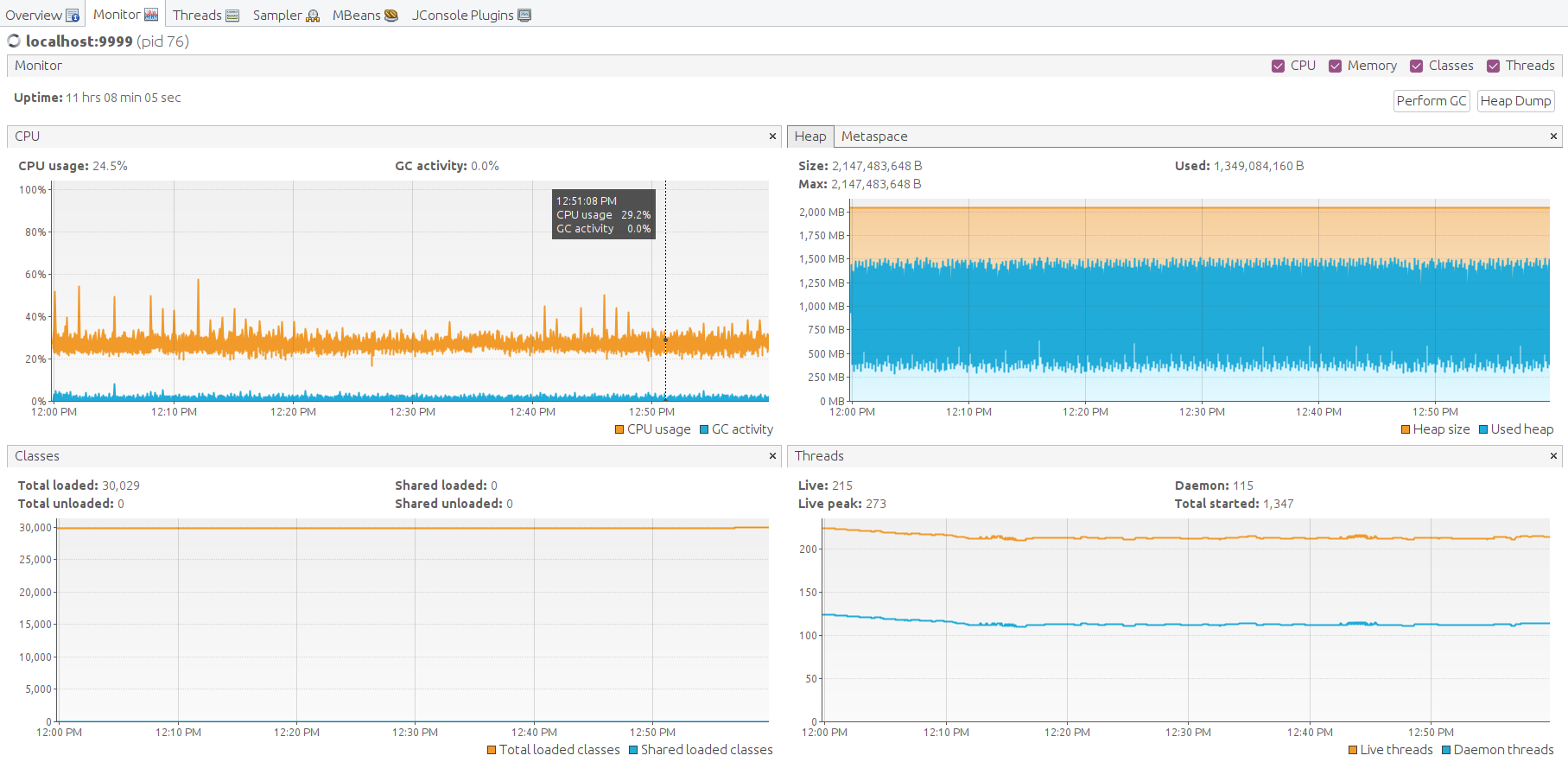
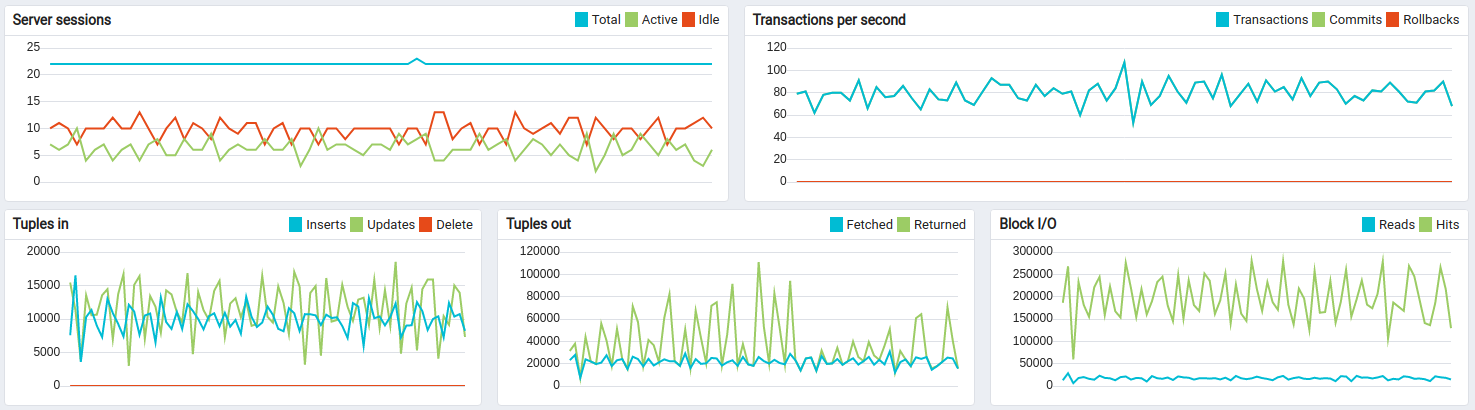
This is a good trade-off configuration to survive and handle message burst with shared CPU instance type and in-memory queue.
However, the shared CPU instances did not guarantee that additional CPU resources will be available at any moment. So you can starve with the base CPU level (20% for t3.medium) at the most important moment. The best practice approach is to set up a persistent queue service like a Kafka and handle the high load whether it is possible.
x10 peak load & eventual crash due to OOM
Load configuration:
- 5000 devices;
- 10000 msg/sec over MQTT, each mqtt message contains 3 data points resulting in 30000 data points/sec;
- PostgreSQL Database;
- In-memory queue.
Instance: AWS t3.medium (2 vCPUs Intel, 4 GiB, EBS GP3)
Let’s burn this tiny instance with x10 message rate! The goal is to provide an example of inadequate platform setup and help the community to avoid wrong deployment decisions.
So let’s generate some message rate spike. CPU and disk will not be able to process all the messages. Some lag will build up. Let’s see what is happening inside the memory and the consequences of the in-memory queue flood.
Launch performance test tool
Use the Docker command listed below to launch the performance test tool based on the instruction.
1
2
3
4
5
6
7
8
9
10
11
# Put your ThingsBoard private IP address here, assuming both ThingsBoard and performance tests EC2 instances are in same VPC.
export TB_INTERNAL_IP=172.31.16.229
docker run -it --rm --network host --name tb-perf-test \
--env REST_URL=http://$TB_INTERNAL_IP:8080 \
--env MQTT_HOST=$TB_INTERNAL_IP \
--env DEVICE_END_IDX=5000 \
--env MESSAGES_PER_SECOND=10000 \
--env ALARMS_PER_SECOND=10 \
--env DURATION_IN_SECONDS=86400 \
--env DEVICE_CREATE_ON_START=false \
thingsboard/tb-ce-performance-test:3.3.3
In the beginning, the system looks busy but responsive.
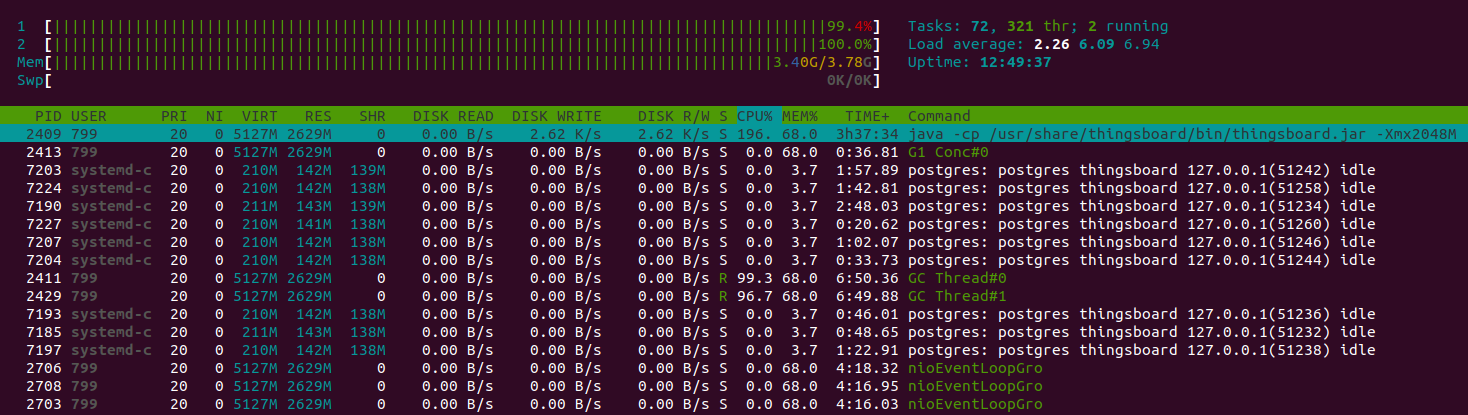
Then the instance becomes short on memory, and overall performance will degrade.
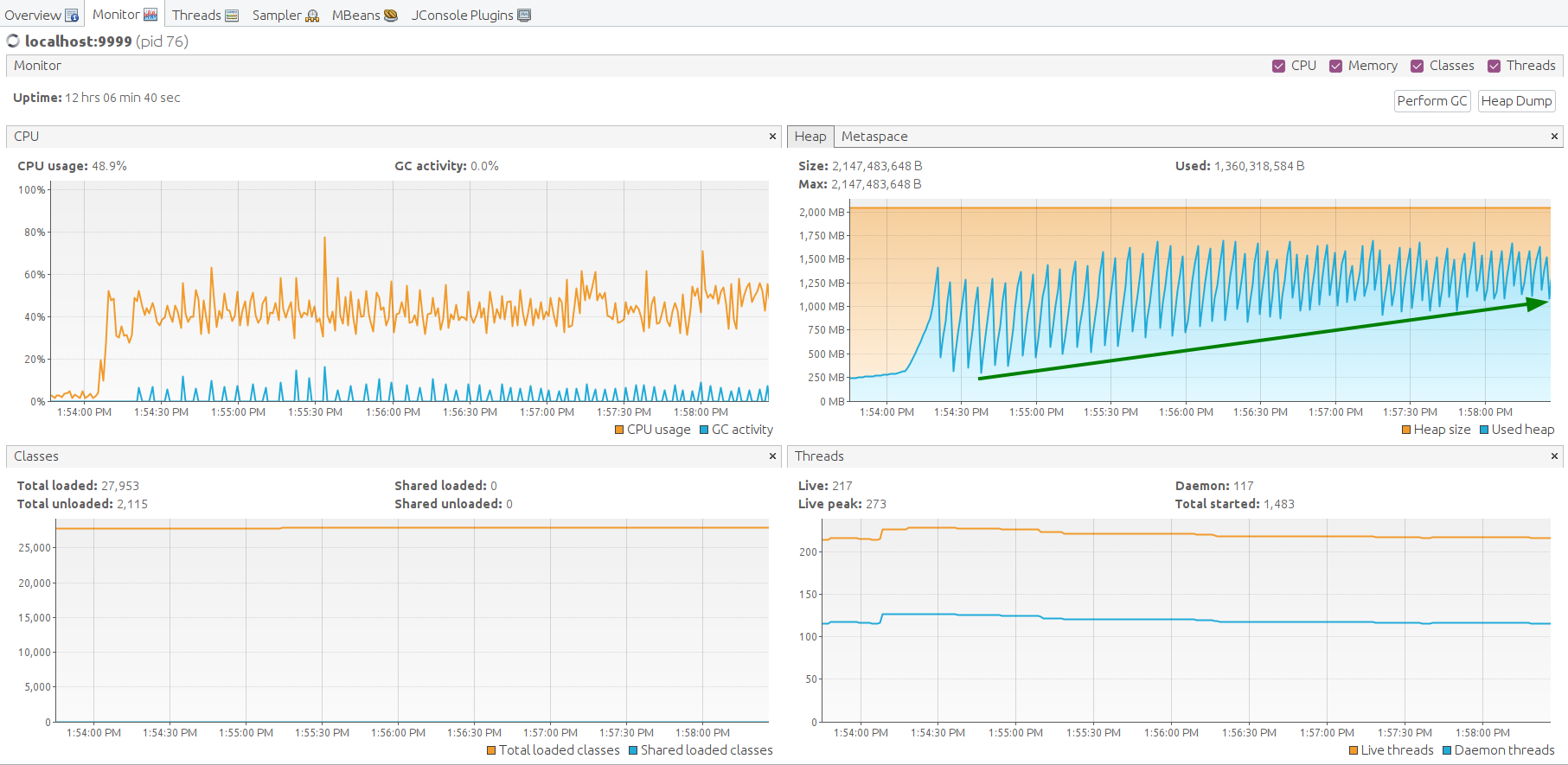
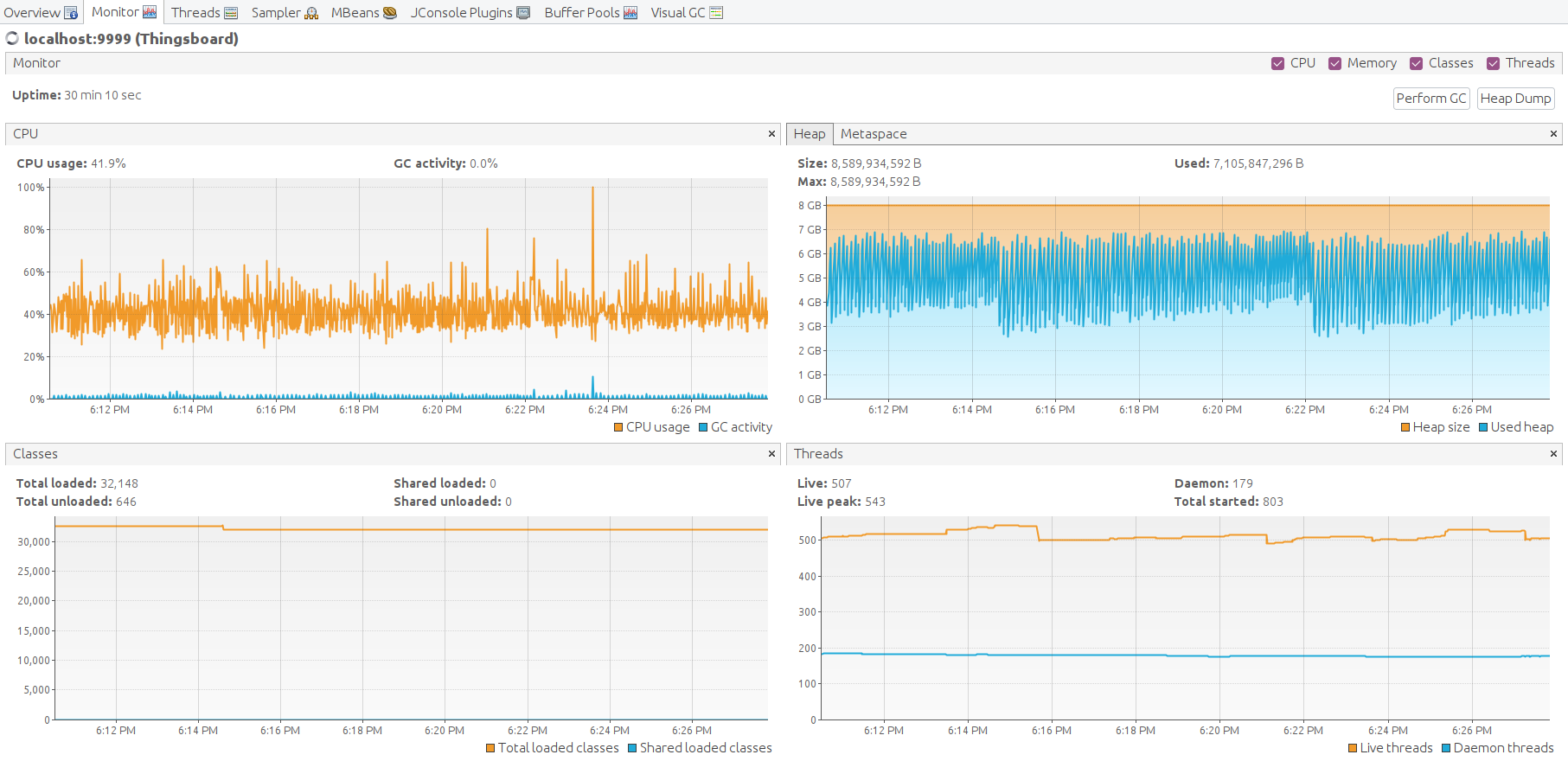
Now we see that heap memory used is constantly growing on the JMX monitor.
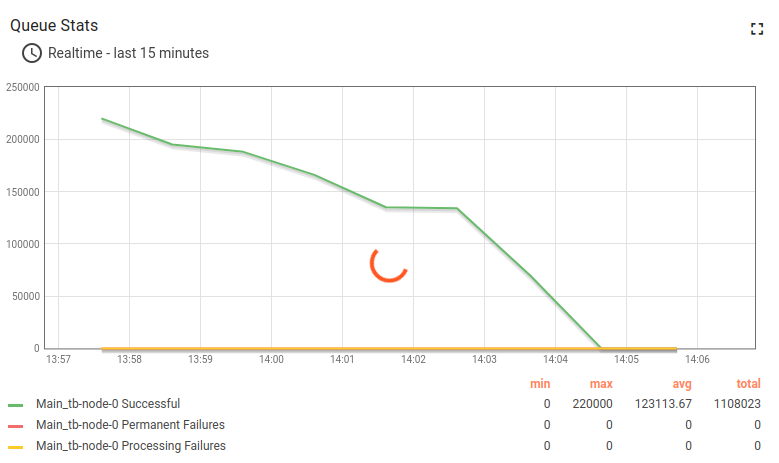
It takes about 10 minutes to flood all the memory, and the system becomes unresponsive.
Queue stats drop to zero and do not respond anymore.
CPU is still 100% load, but mainly spending on the garbage collector.
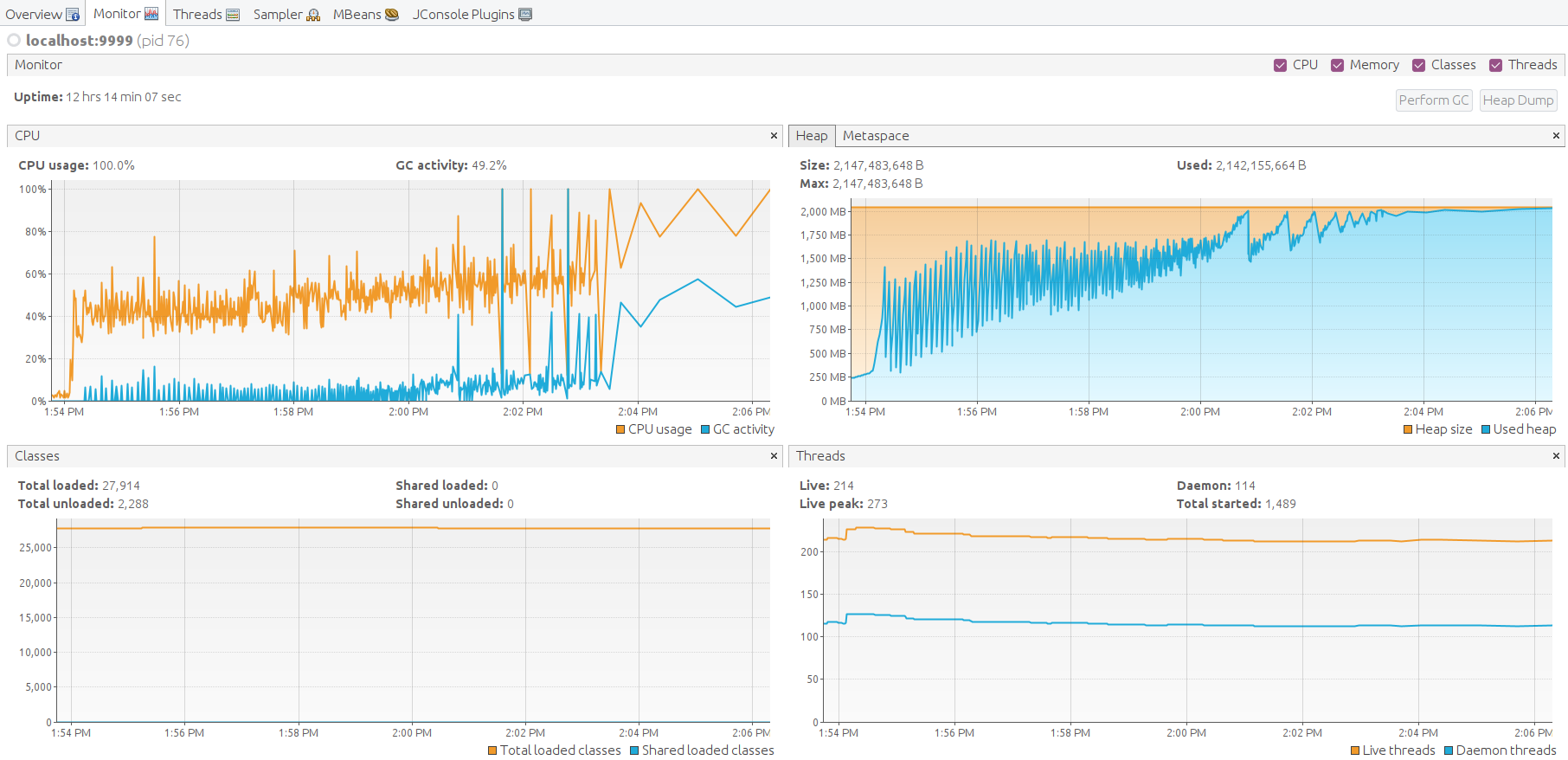
JMX VusialVM monitoring shows how the system dies due to out-of-memory.
In the next 3 minutes, the system will fail.

Why does it happen?
The root cause of the problem is usage of the in-memory queue. All the unprocessed messages are stored in the RAM and eventually the system simply runs out of memory.
Any solutions? Yes! Please consider using a persistent queue type to make the system much more reliable and peak resistant. Kafka is a good one.
Jump to Scenario B for more details.
Kafka + Postgres performance
Scenario B
Load configuration:
- 5000 devices;
- 5000 msg/sec over MQTT, each mqtt message contains 3 data points resulting in 15000 data points/sec;
- PostgreSQL Database;
- Kafka queue.
Instance: AWS m6a.large (2 vCPUs AMD EPYC 3rd, 8 GiB, EBS GP3)
Estimated cost: 42$ EC2 + 8$ EBS GP3 100GB = 50$/mo, disk space for telemetry may add additional costs.
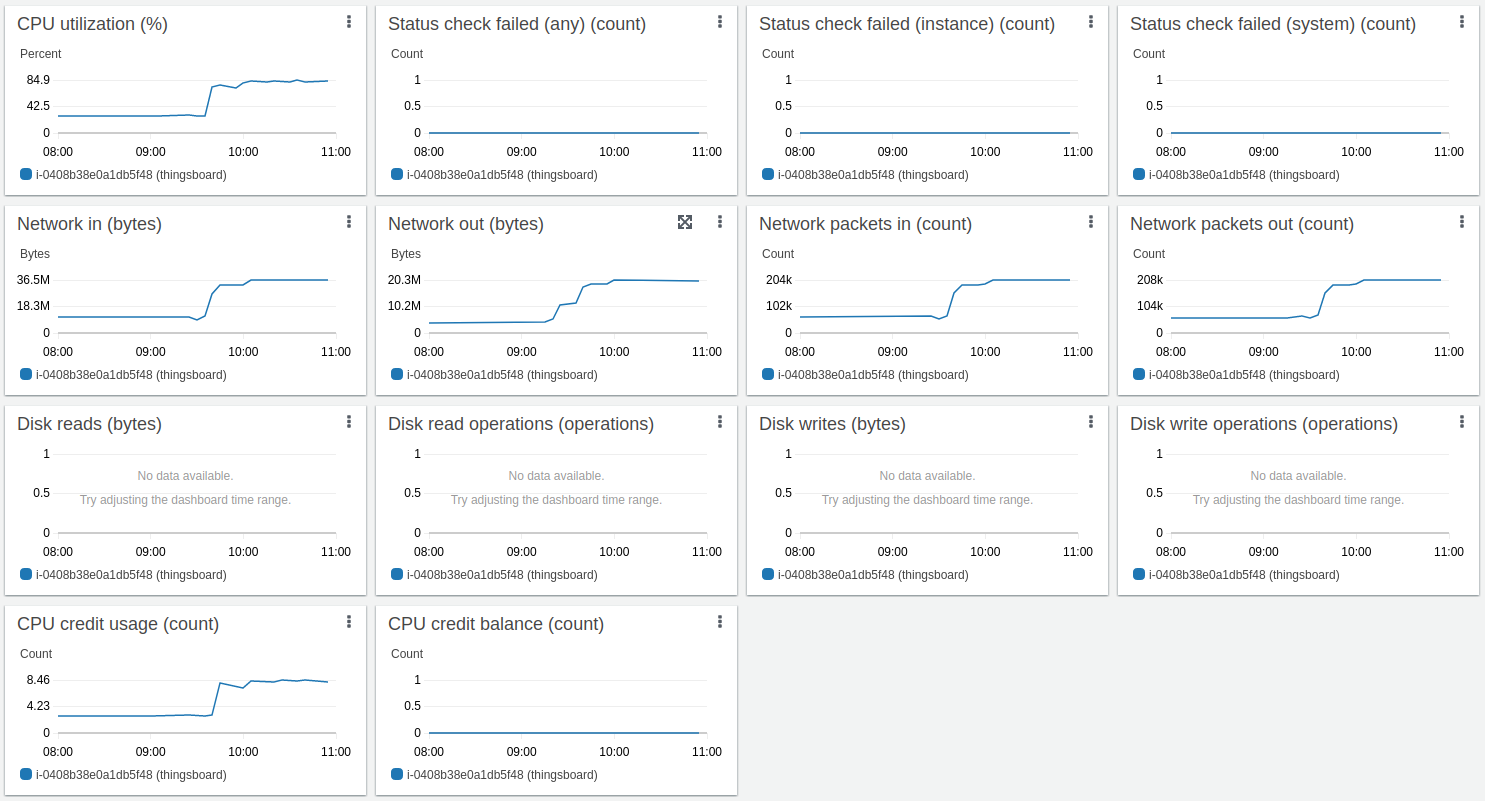
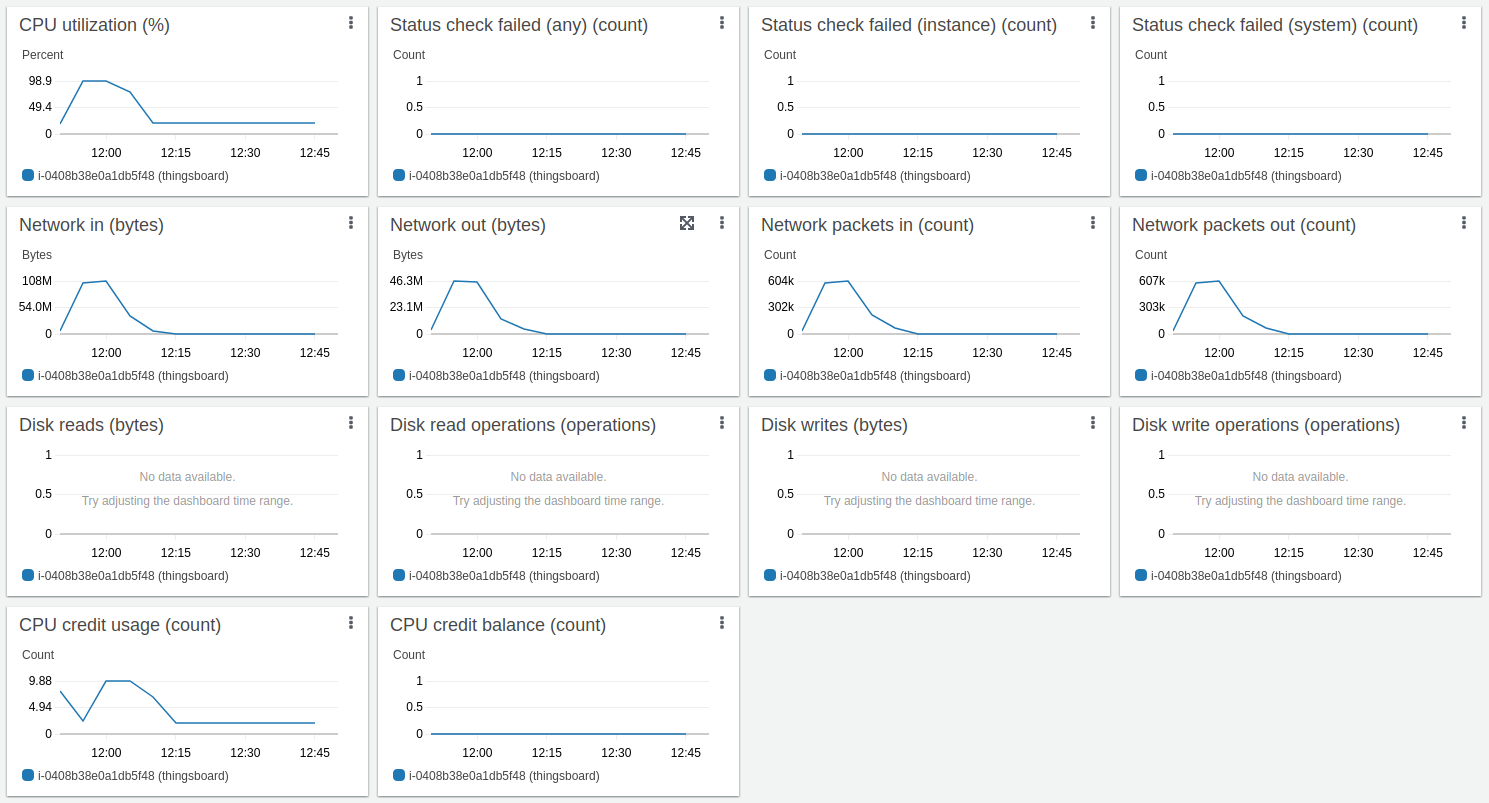
Here results for Kafka + Postgres:
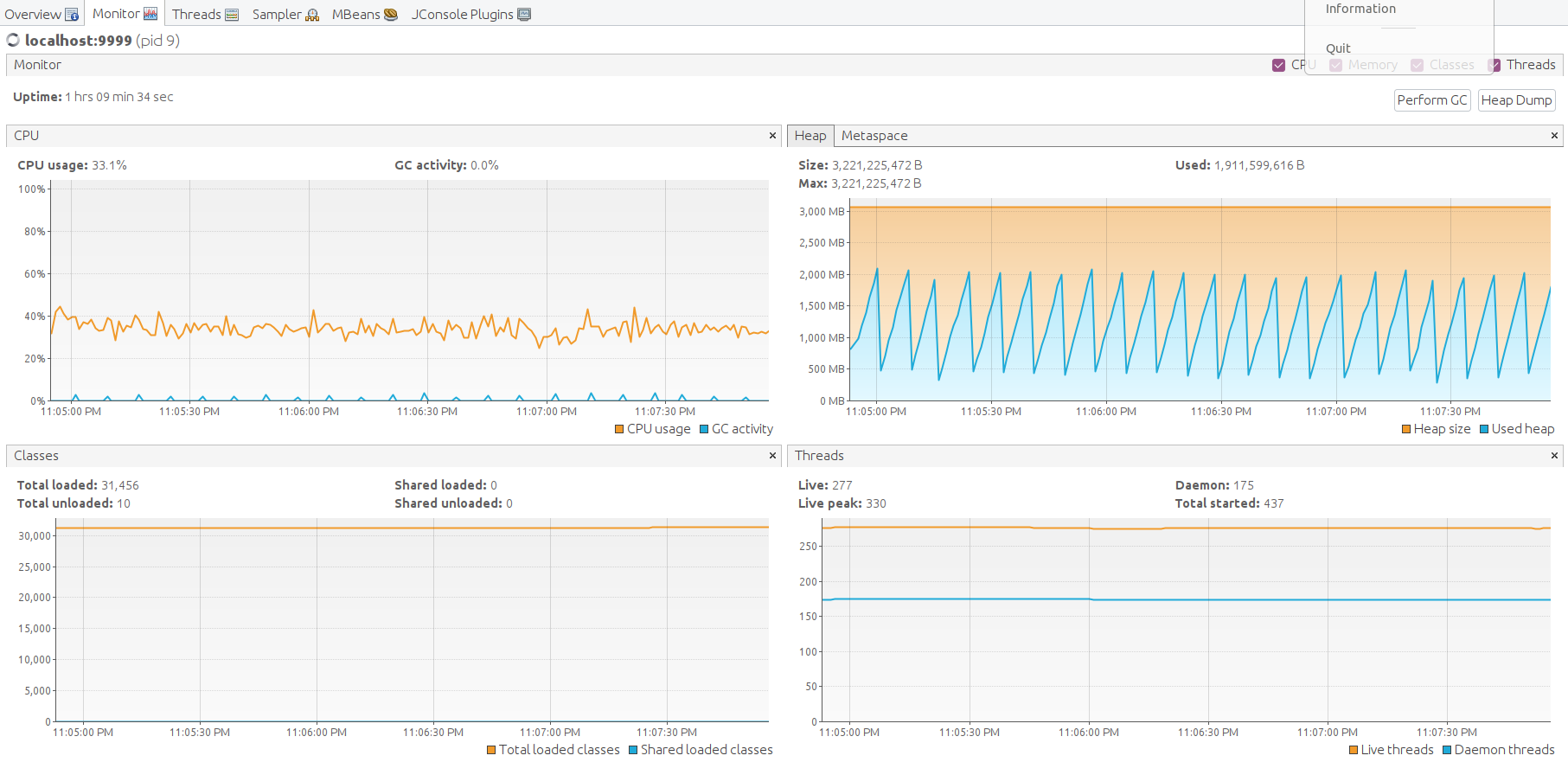
Long-running result about 14 hours:
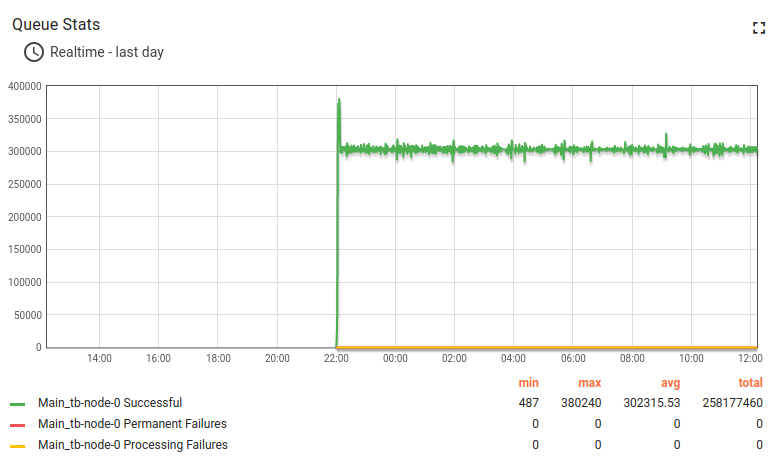
Lessons learned
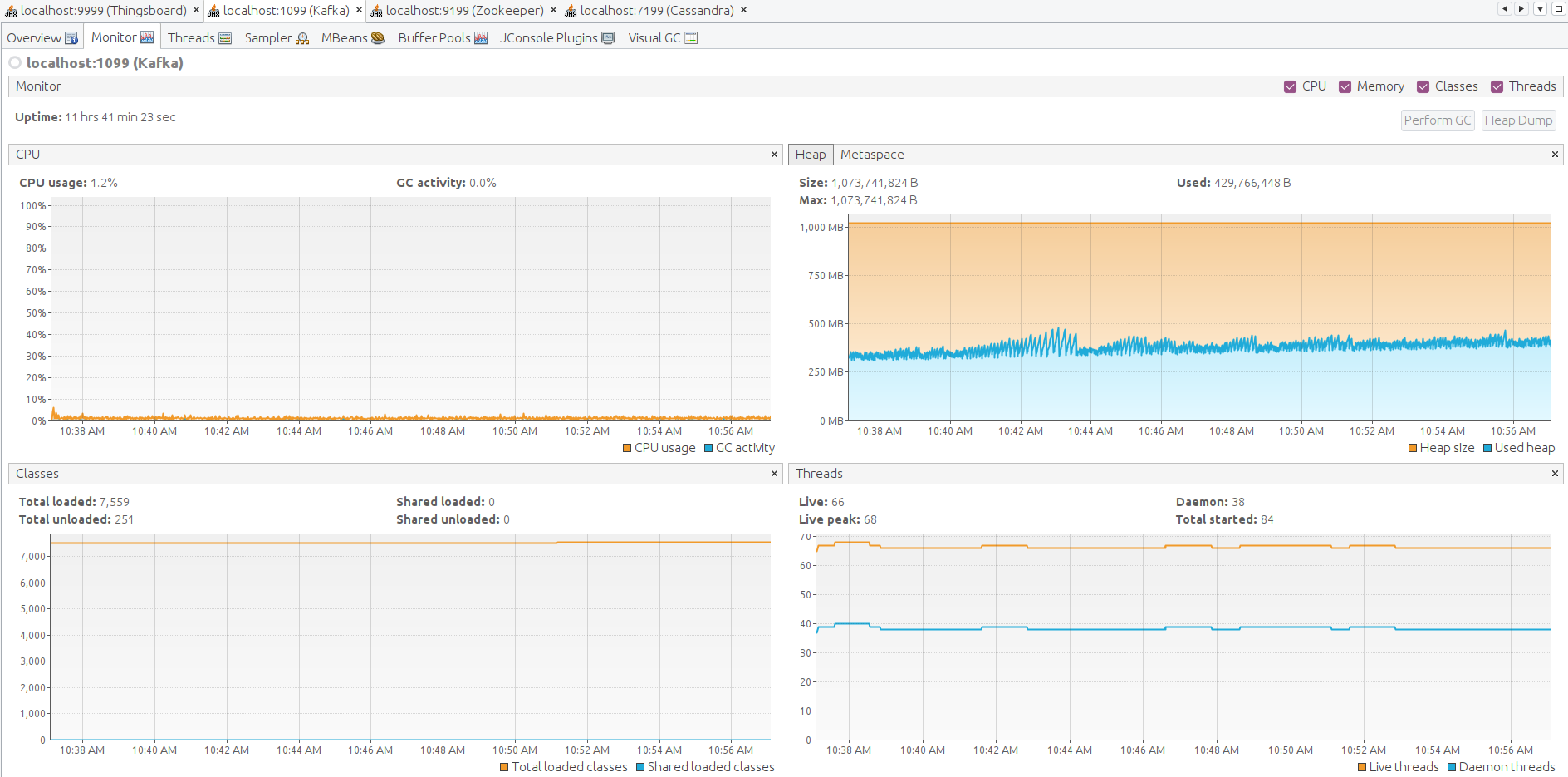
Kafka CPU and disk IO overhead are tiny relative to Postgres and ThingsBoard CPU consumption. The memory footprint is about 1G in default configuration and can be easily adjusted for smaller instances. The persistent queue is essential to survive peak loads.
This is the high load configuration with CPU 95% average utilization for processing 15000 data points/second. This is a good setup up to 10000 data points/second, with peak performance up to 60000 data points/sec (see next test).
Note: You definitely need add more CPU to process some custom rule chains, render your dashboards and maintain stable 5000 msg/sec.
How to reproduce the test:
Setup the ThingsBoard instance on AWS EC2
Take a note that Zookeeper is required to run Kafka these days. Here is the docker-compose file to set up ThingsBoard + Postgresql + Zookeeper + Kafka on AWS EC2 instance based on the instruction.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
version: '3.0'
services:
zookeeper:
image: bitnamilegacy/zookeeper:3.7
network_mode: "host"
restart: "always"
volumes:
- zookeeper:/bitnami
environment:
ALLOW_ANONYMOUS_LOGIN: "yes"
ZOO_ENABLE_ADMIN_SERVER: "no"
JVMFLAGS: "-Xmx128m -Xms128m -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9199 -Dcom.sun.management.jmxremote.rmi.port=9199 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
kafka:
image: bitnamilegacy/kafka:3
network_mode: "host"
restart: "always"
volumes:
- kafka:/bitnami
environment:
- KAFKA_CFG_ZOOKEEPER_CONNECT=localhost:2181
- ALLOW_PLAINTEXT_LISTENER=yes
depends_on:
- zookeeper
postgres:
image: "postgres:14"
network_mode: "host"
restart: "always"
volumes:
- postgres:/var/lib/postgresql/data
environment:
POSTGRES_DB: "thingsboard"
POSTGRES_PASSWORD: "postgres"
tb:
depends_on:
- postgres
- kafka
image: "thingsboard/tb"
network_mode: "host"
restart: "always"
volumes:
- thingsboard-data:/data
- thingsboard-logs:/var/log/thingsboard
environment:
DATABASE_TS_TYPE: "sql"
TB_QUEUE_TYPE: "kafka"
TB_KAFKA_BATCH_SIZE: "65536" # default is 16384 - it helps to produce messages much efficiently
TB_KAFKA_LINGER_MS: "5" # default is 1
TB_QUEUE_KAFKA_MAX_POLL_RECORDS: "2048" # default is 8192
TB_SERVICE_ID: "tb-node-0"
HTTP_BIND_PORT: "8080"
TB_QUEUE_RE_MAIN_PACK_PROCESSING_TIMEOUT_MS: "30000"
# Postgres connection
SPRING_DATASOURCE_URL: "jdbc:postgresql://localhost:5432/thingsboard"
SPRING_DATASOURCE_USERNAME: "postgres"
SPRING_DATASOURCE_PASSWORD: "postgres"
# Java options for 8G instance and JMX enabled
JAVA_OPTS: " -Xmx3072M -Xms3072M -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.rmi.port=9999 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
volumes: # to persist data between container restarts or being recreated
kafka:
zookeeper:
postgres:
thingsboard-data:
thingsboard-logs:
Launch performance test tool
Use the Docker command listed below to launch the performance test tool based on the instruction.
1
2
3
4
5
6
7
8
9
10
11
# Put your ThingsBoard private IP address here, assuming both ThingsBoard and performance tests EC2 instances are in same VPC.
export TB_INTERNAL_IP=172.31.16.229
docker run -it --rm --network host --name tb-perf-test \
--env REST_URL=http://$TB_INTERNAL_IP:8080 \
--env MQTT_HOST=$TB_INTERNAL_IP \
--env DEVICE_END_IDX=5000 \
--env MESSAGES_PER_SECOND=5000 \
--env ALARMS_PER_SECOND=50 \
--env DURATION_IN_SECONDS=86400 \
--env DEVICE_CREATE_ON_START=true \
thingsboard/tb-ce-performance-test:3.3.3
x3 peak load survival
Load configuration:
- 5000 devices;
- 15000 msg/sec over MQTT, each mqtt message contains 3 data points resulting in 45000 data points/sec;
- PostgreSQL Database;
- Kafka queue.
Instance: AWS m6a.large (2 vCPUs AMD EPYC 3rd, 8 GiB, EBS GP3)
Let’s take a stress test to find out how the Kafka bring the stability into operations.
Statistics related to the test execution:
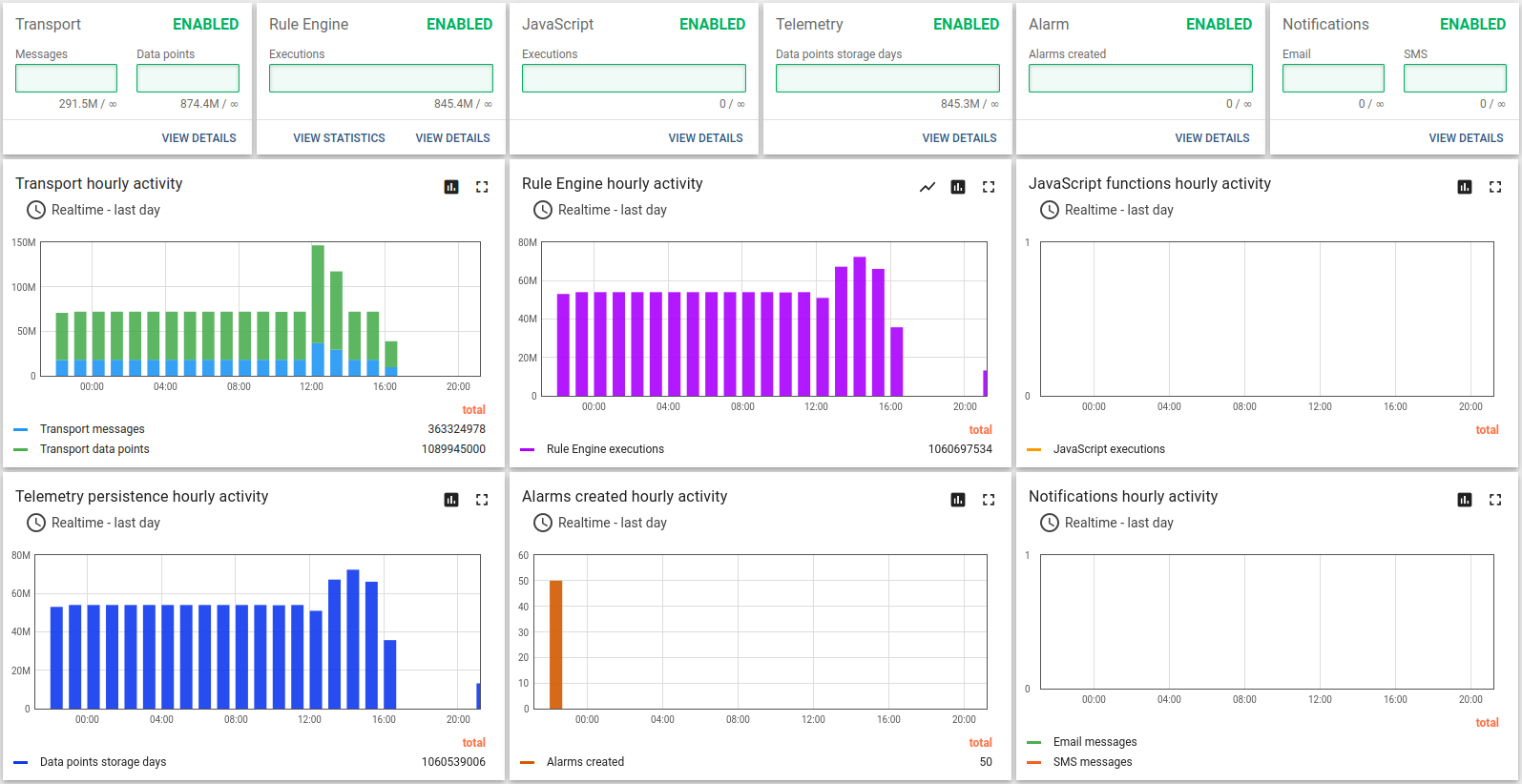

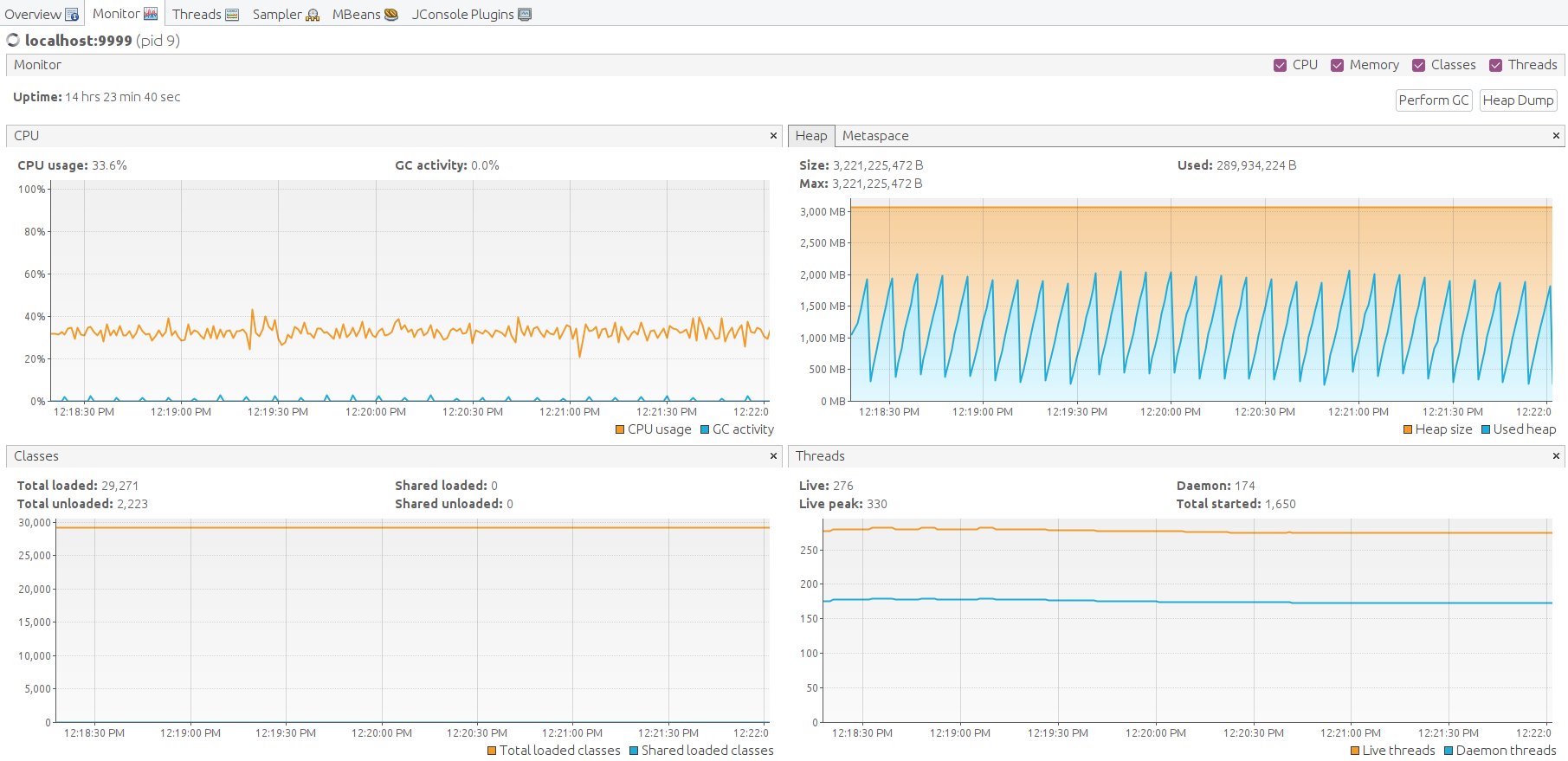
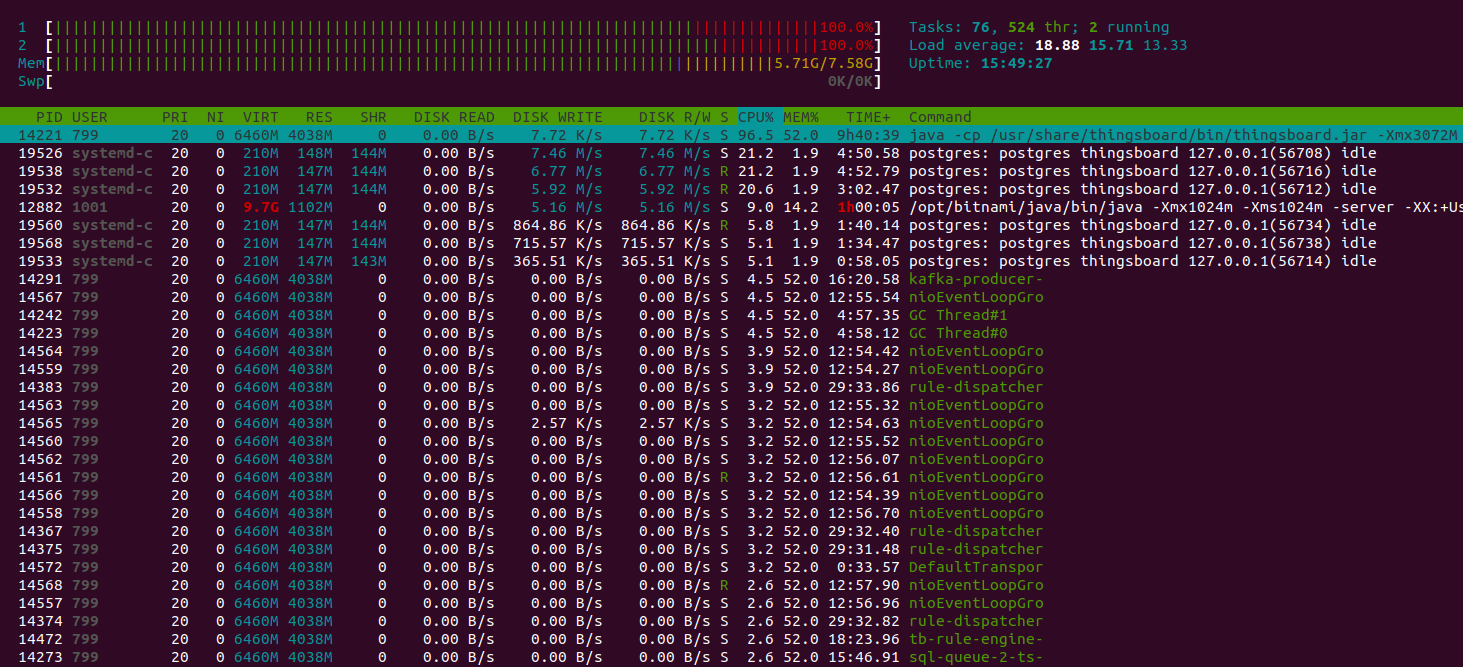
We can see 100% CPU utilization. The system is overloaded. However, all non-processed messages are stored in Kafka and will be eventually processed by rule engine.
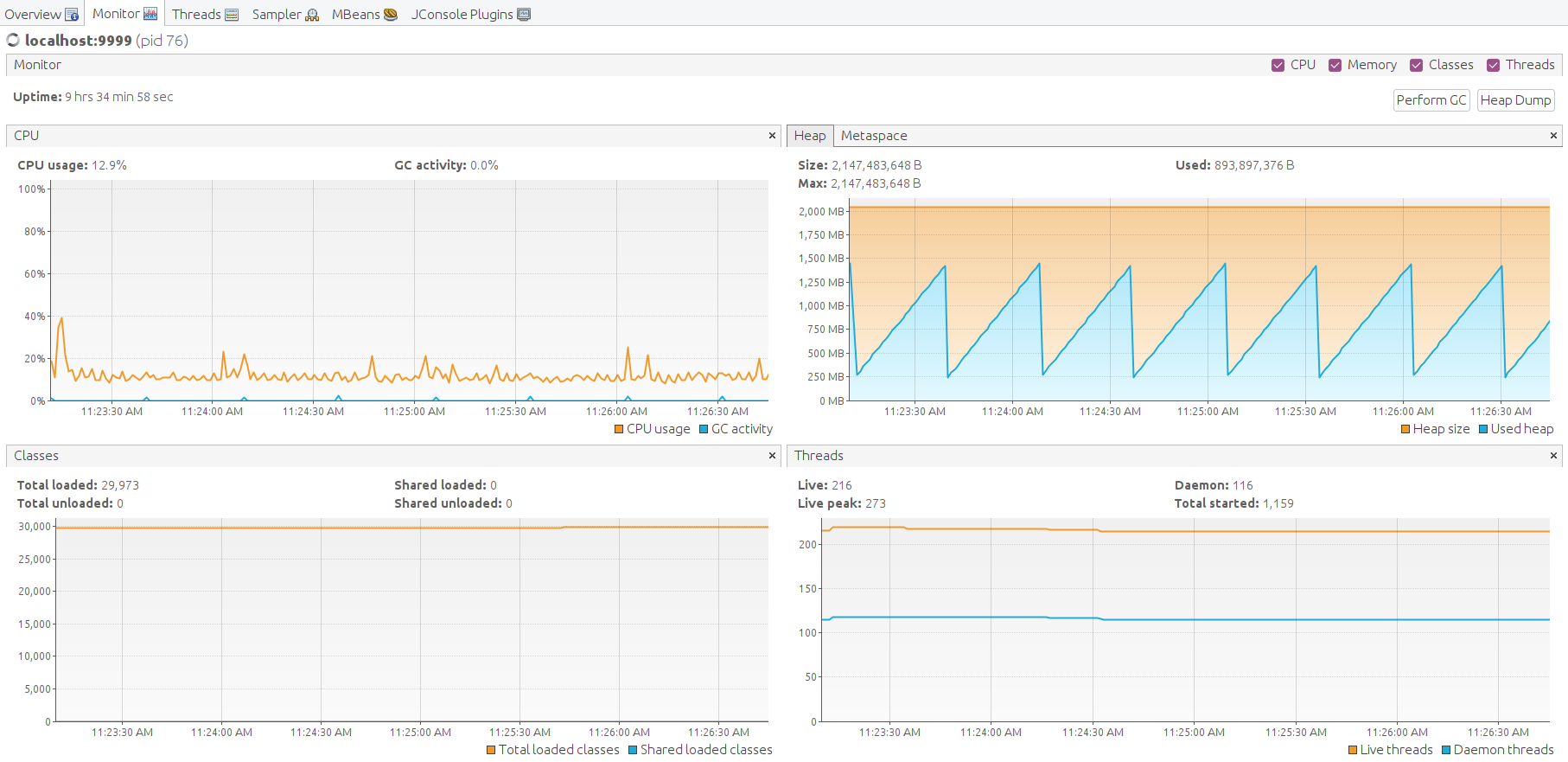
Java machine feels good. Heap memory has enough space to operate. Let’s perform garbage collection manually to find the lowest point of the memory consumption. The free memory level goes back to the average level. That is a good result.
Another way to ensure that we run stable is to check the Kafka producer state with JMX MBean.
Kafka Lag is building up. That means that the rule engine processing speed is lower than incoming message rate.
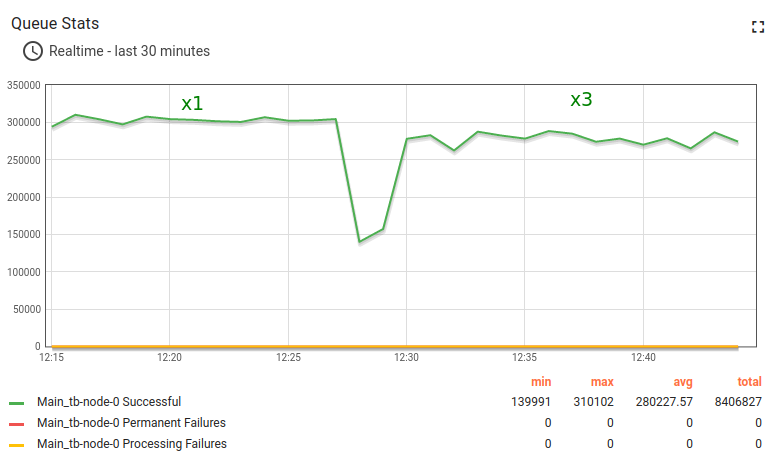
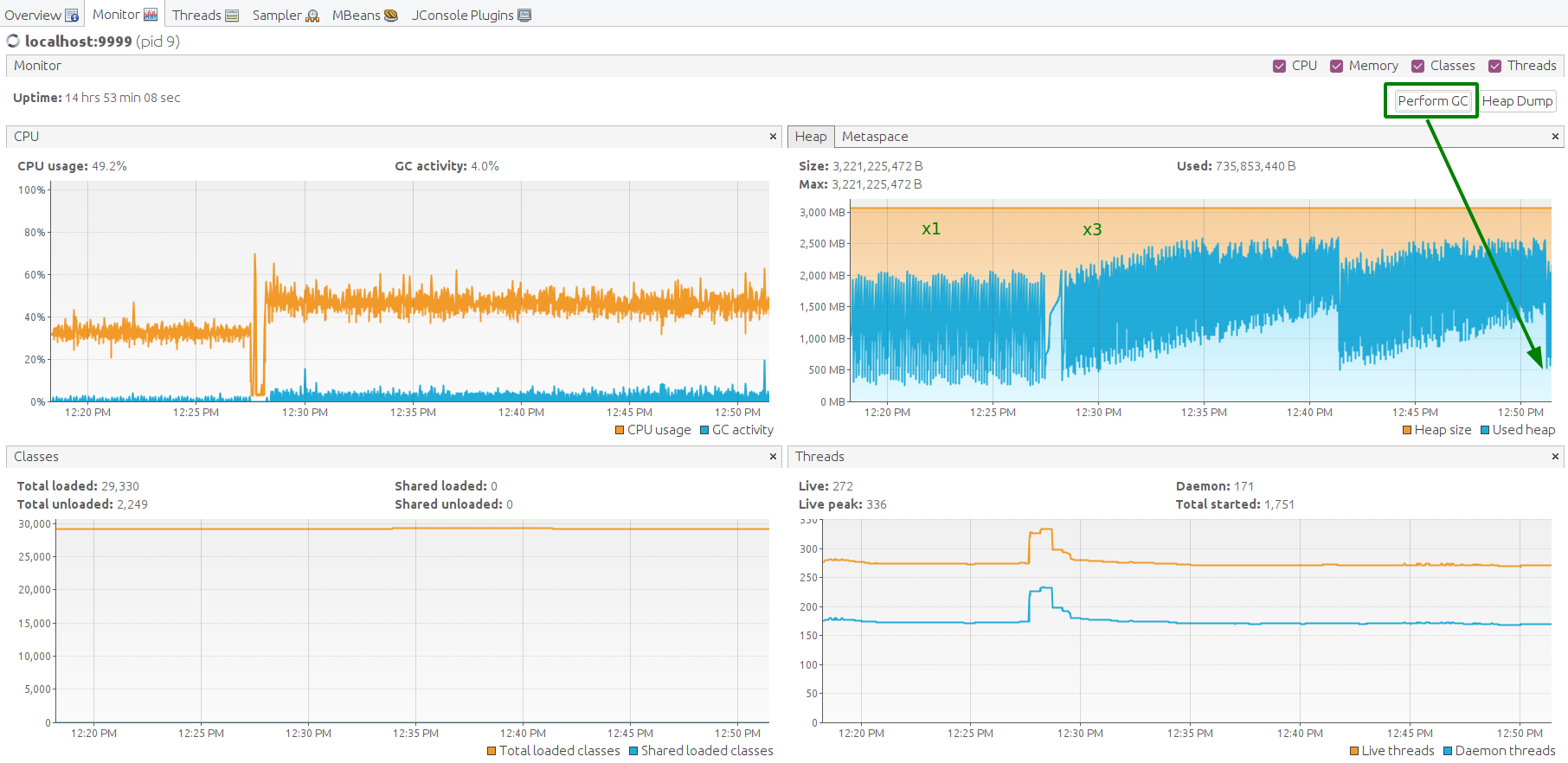
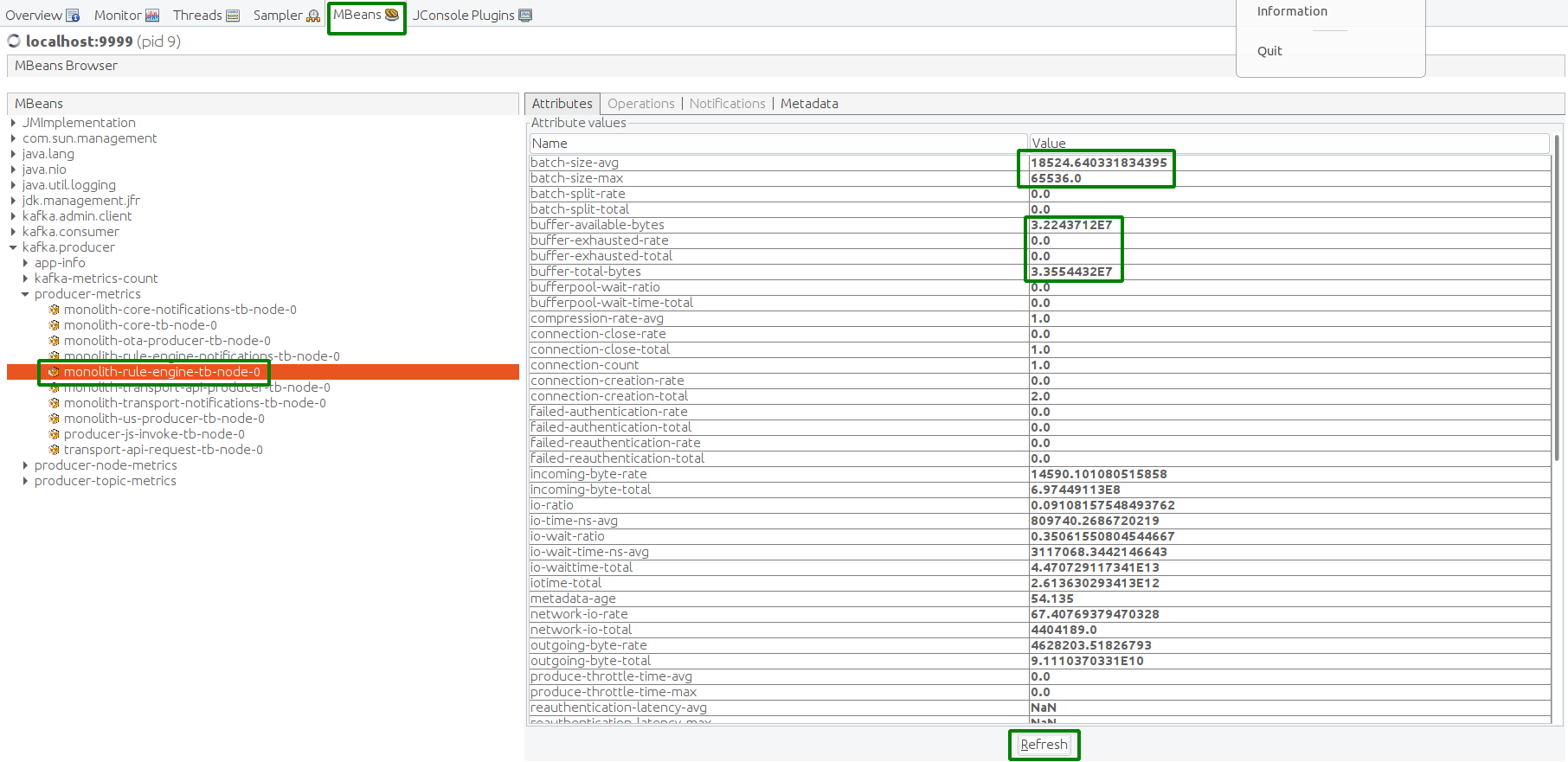

Now let’s stop the x3 test and get back to the average message rate (5000 msg/sec) in a minute.
After a while, we may see that the lag is going down from 2.8M to 1.2M. Eventually, the numbers back to nominal.
Launch performance test tool
Use the Docker command listed below to launch the performance test tool based on the instruction.
1
2
3
4
5
6
7
8
9
10
11
# Put your ThingsBoard private IP address here, assuming both ThingsBoard and performance tests EC2 instances are in same VPC.
export TB_INTERNAL_IP=172.31.16.229
docker run -it --rm --network host --name tb-perf-test \
--env REST_URL=http://$TB_INTERNAL_IP:8080 \
--env MQTT_HOST=$TB_INTERNAL_IP
--env DEVICE_END_IDX=5000 \
--env MESSAGES_PER_SECOND=15000 \
--env ALARMS_PER_SECOND=50 \
--env DURATION_IN_SECONDS=86400 \
--env DEVICE_CREATE_ON_START=false \
thingsboard/tb-ce-performance-test:3.3.3
Lessons learned
ThingsBoard + Postgres + Kafka - is a reliable solution to survive peak loads.
Despite the maximum performance shown above, we recommend to use m6a.large instance design for up to 3k msg/sec, 10k data points/sec.
The logic is quite simple: to be able to process x2 message load in case of any peak load.
In a real production, the ThingsBoard may serve all kind of user requests, run custom rule chains and supply the web services for all fancy dashboards.
When you need more performance, simply upgrade the instance to the next m6a.xlarge or c6i.xlarge instance (restart required).
Another way to improve is to customize PostgreSQL config to gain much faster read query performance for dashboards, analytics, etc.
For even more performance, please consider the Cassandra usage.
Pros:
- Reliable solution to survive the peak load
- Reasonable price for performance and reliability
- Able to scale (vertically).
- Narrow technology stack (Postgres, Kafka)
Cons:
- The telemetry storage consumption is quite intensive. It may become expensive if the telemetry time-to-live (TTL) is a year or infinite.
- Scale only vertical (faster instance, more storage IOPS) - very limited by hardware available and become expensive.
- Kafka here is a single instance. Messages persist eventually (no fsync called). It causes potential latest message loss if Kafka crashes (quite rare, but possible).
- Maintain or fail any of component will lead to downtime for all the system.
Cassandra + Kafka + Postgres performance
Scenario C
Load configuration:
- 25000 devices;
- 10000 msg/sec over MQTT, each mqtt message contains 3 data points resulting in 30000 data points/sec;
- PostgreSQL database to store entities, attributes and latest values of time-series data;
- Cassandra database to store time-series data;
- Kafka queue.
Instance: AWS m6a.2xlarge (8 vCPUs AMD EPYC 3rd, 32 GiB, EBS GP3)
Estimated cost: 167$ EC2 m6a.2xlarge + 24$ EBS GP3 300GB = 191$/month.
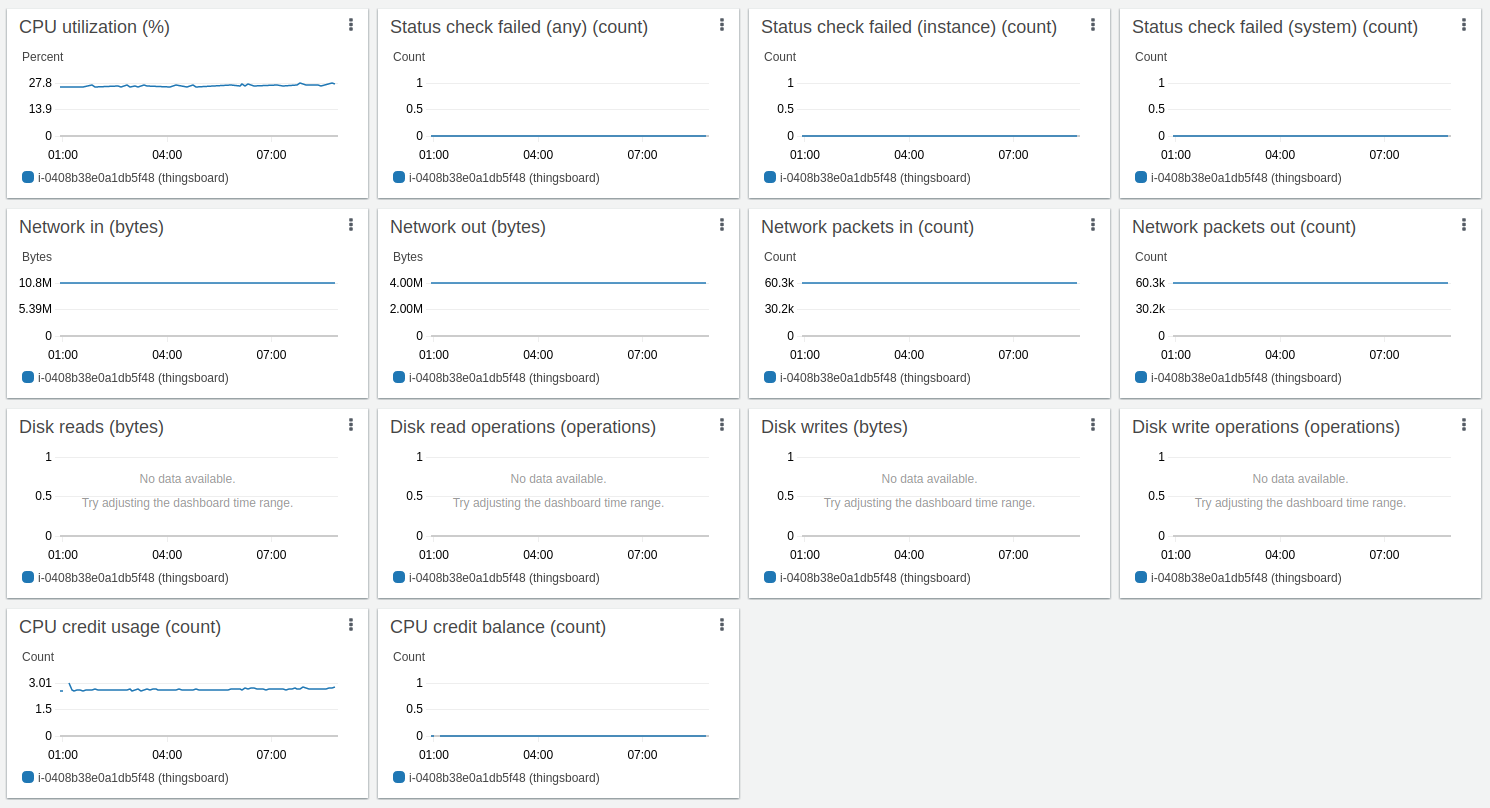
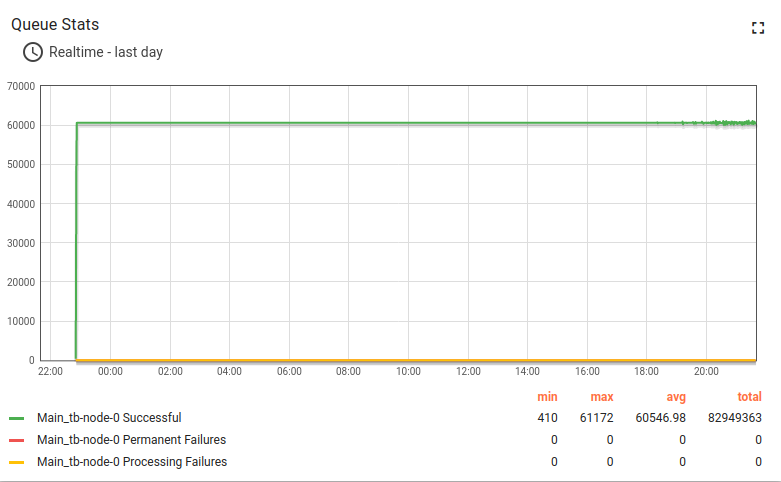
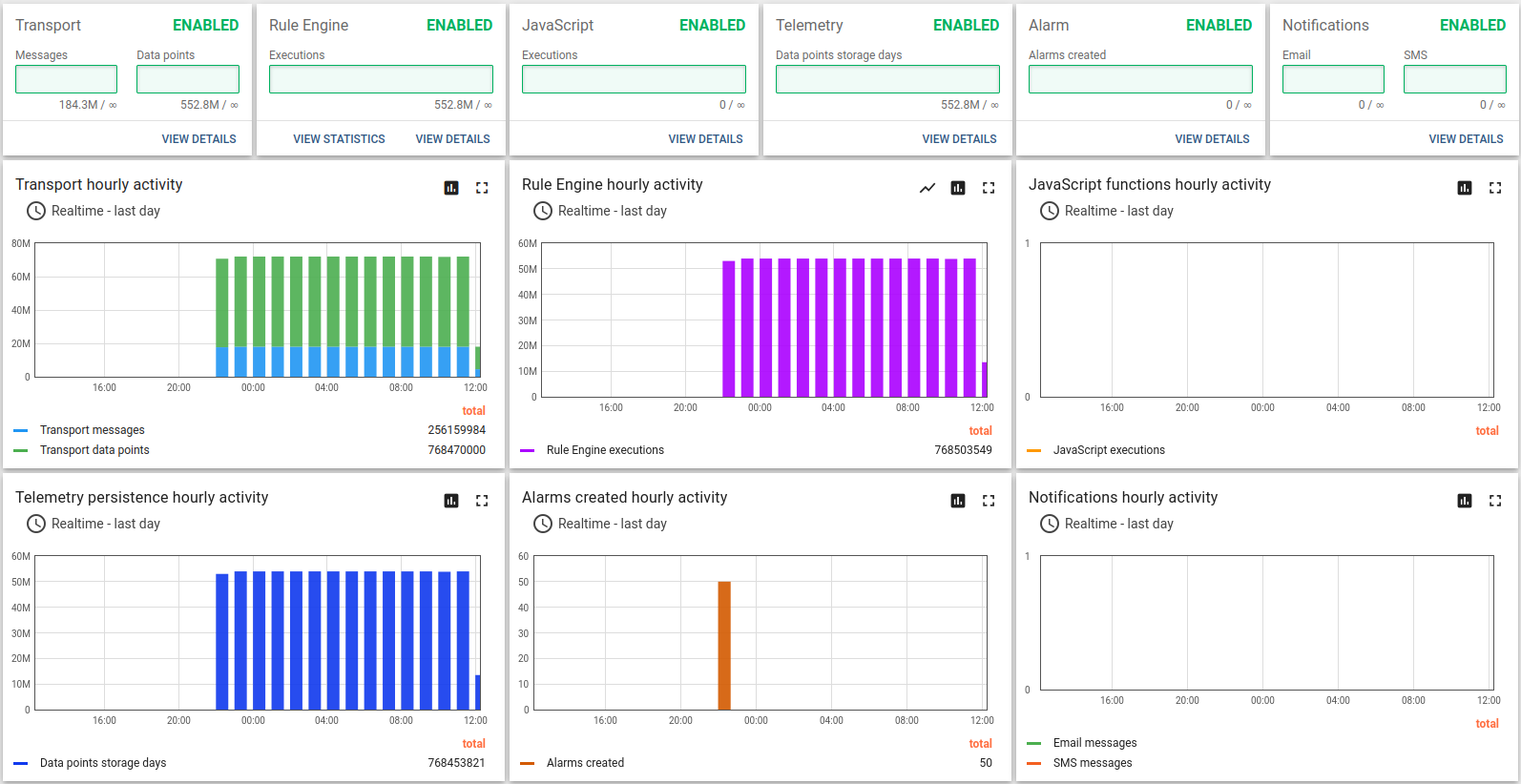
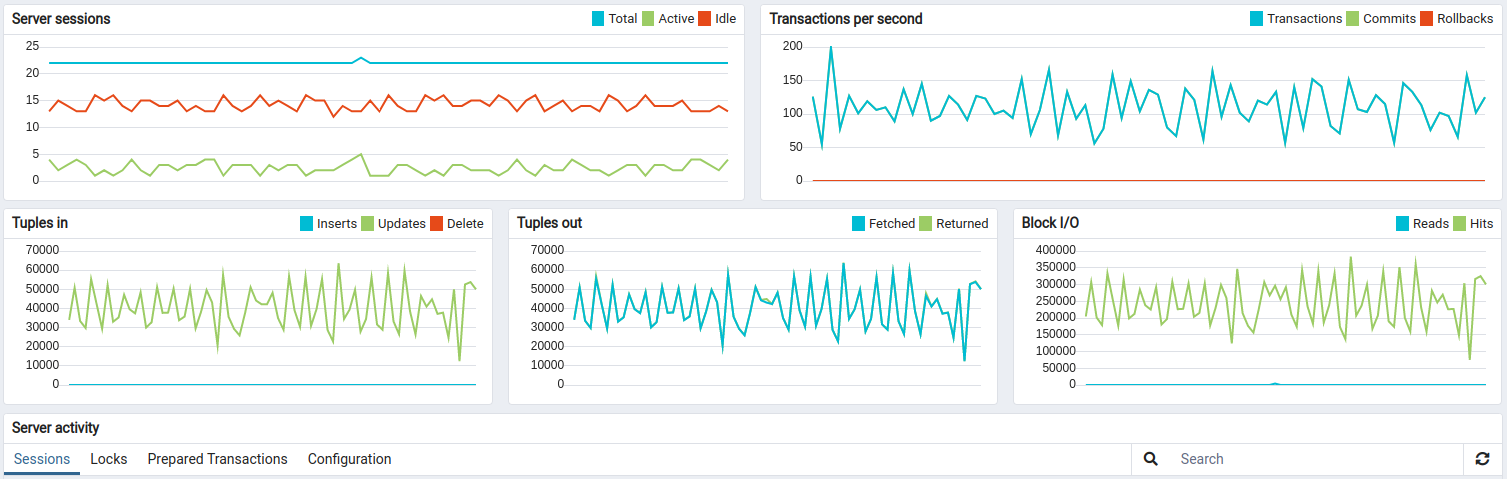
Test run
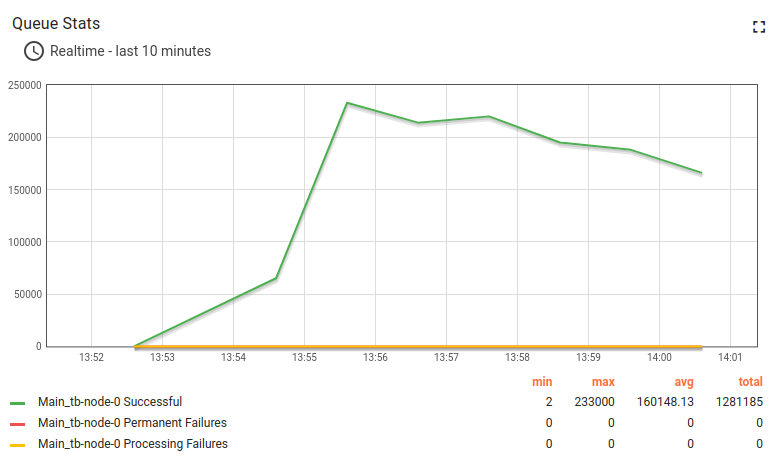
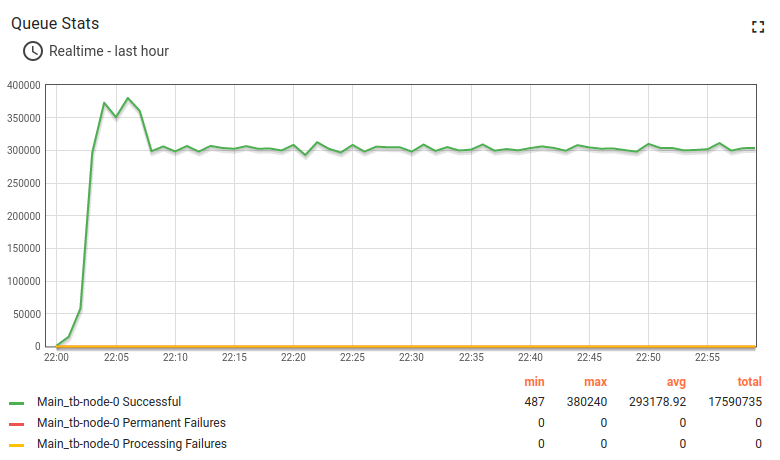
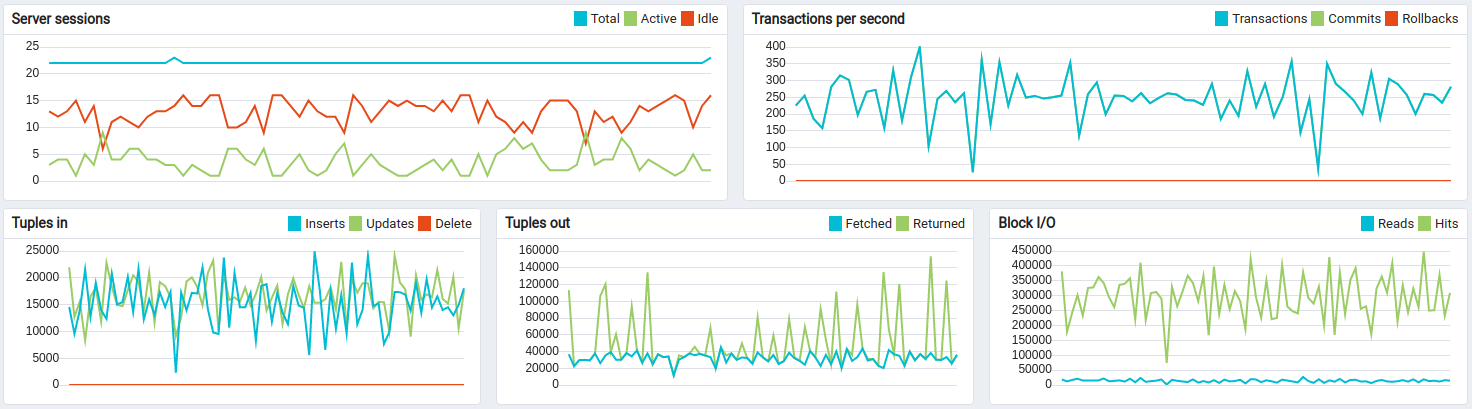
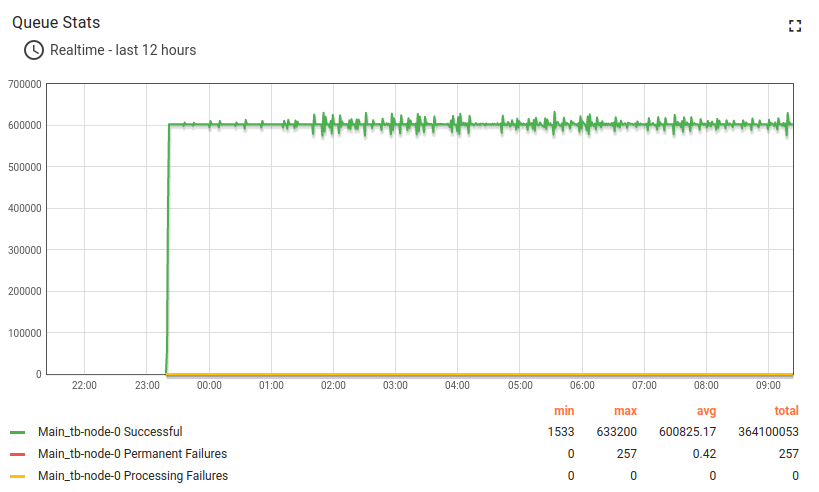
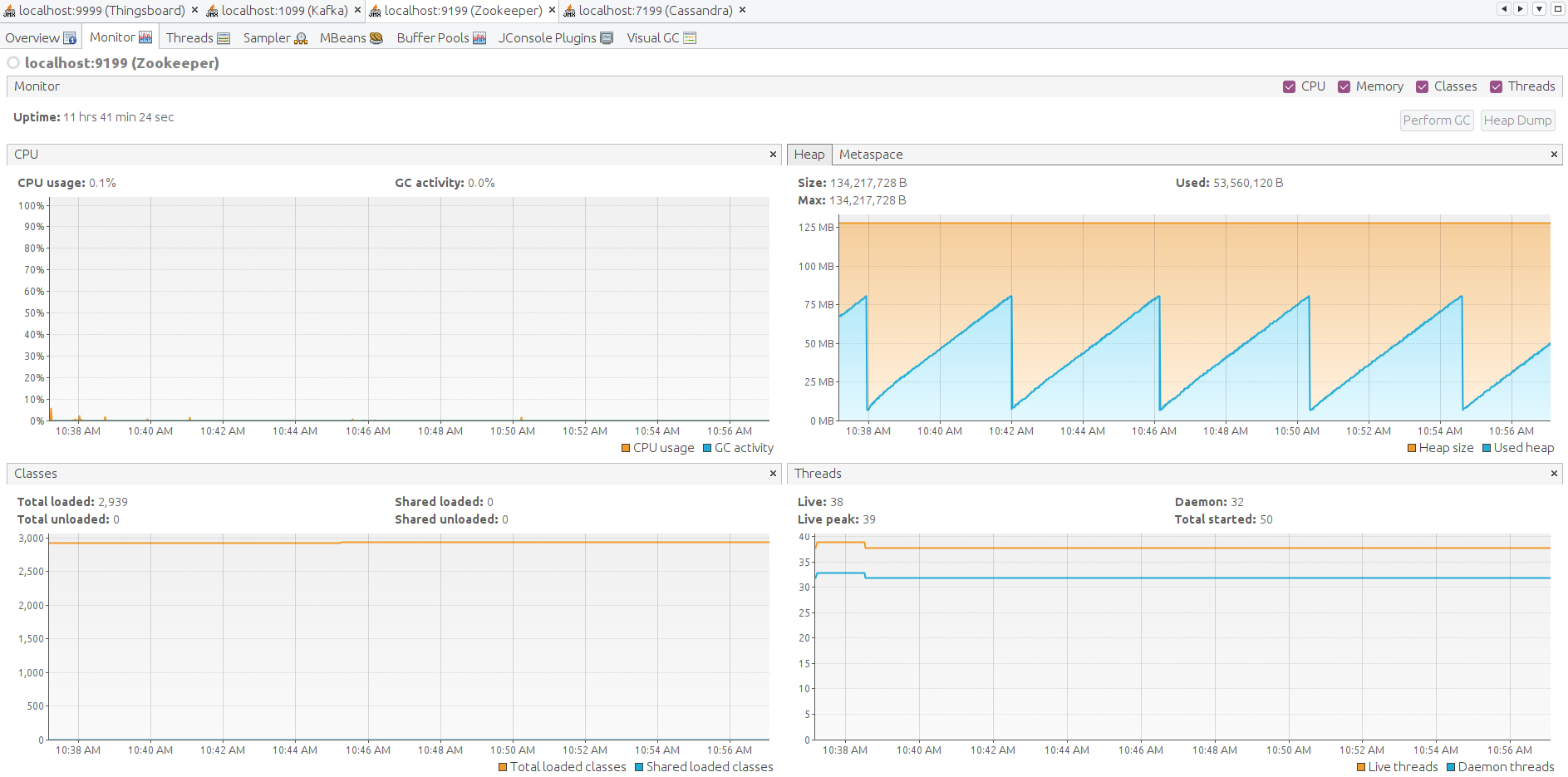
The queue stats looks solid. A small fluctuation on the chart is nominal.
All systems have to run maintenance in background, so it is completely fine to have those chart for ThingsBoard monolith deployment.
The API usage shows about 10 hours and 1.1B data points processed.
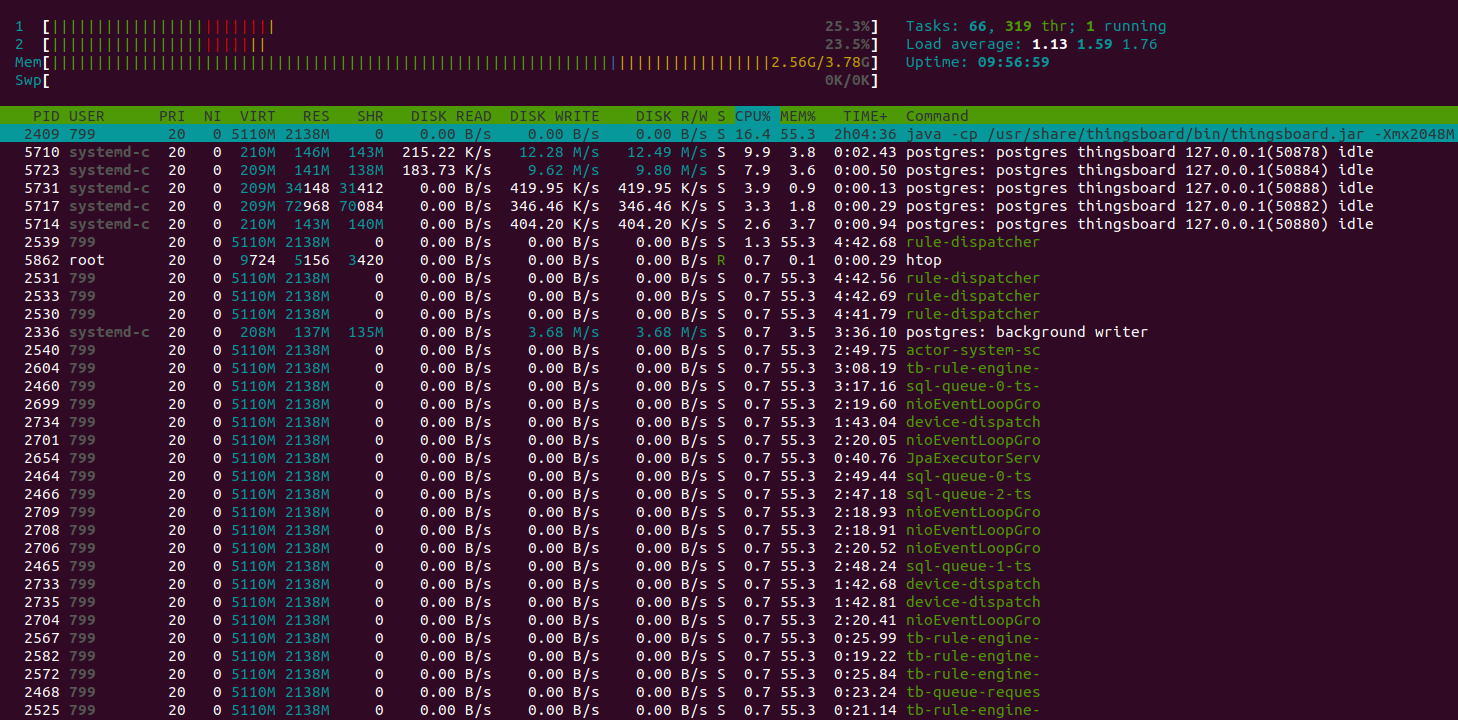
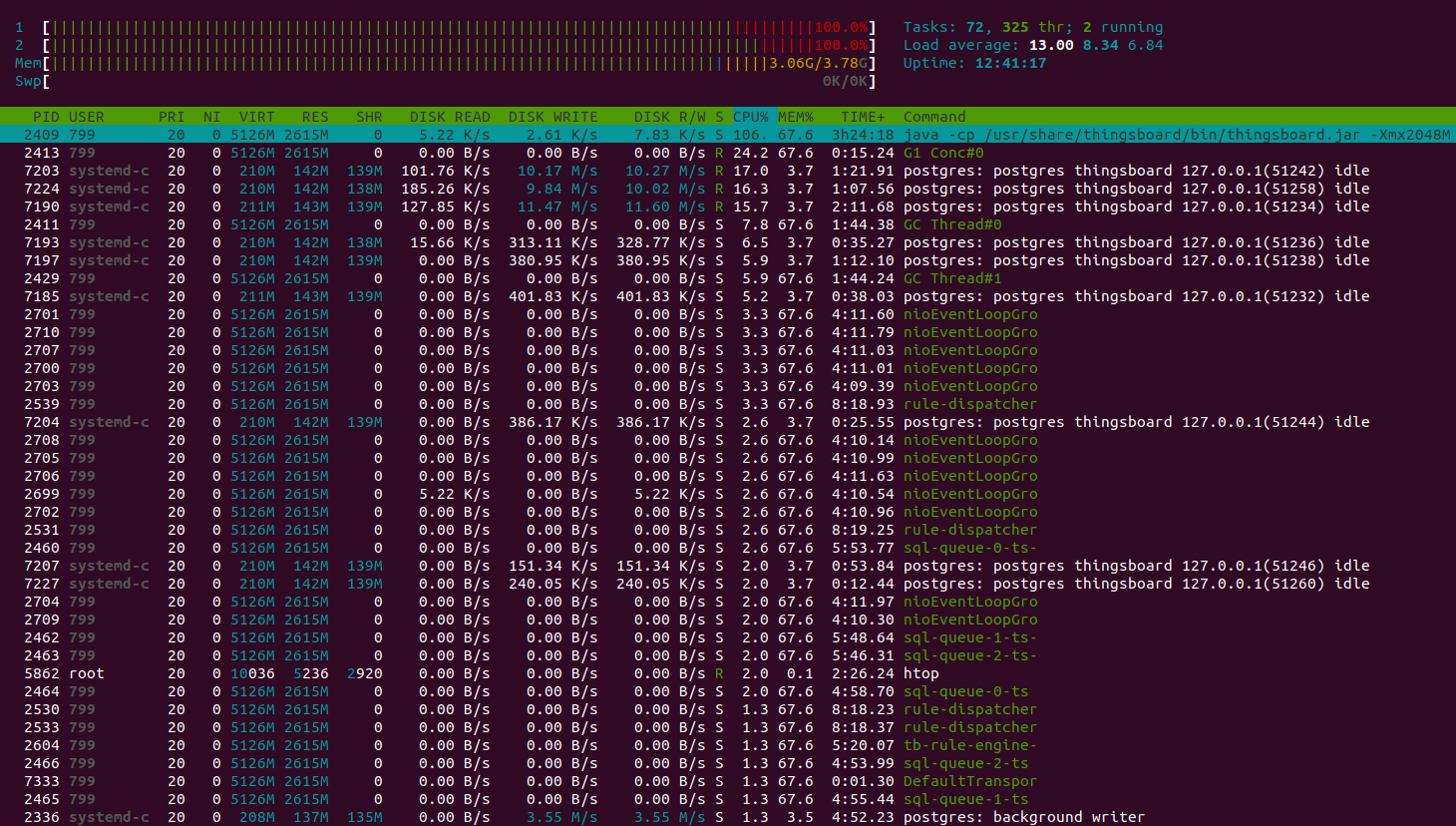
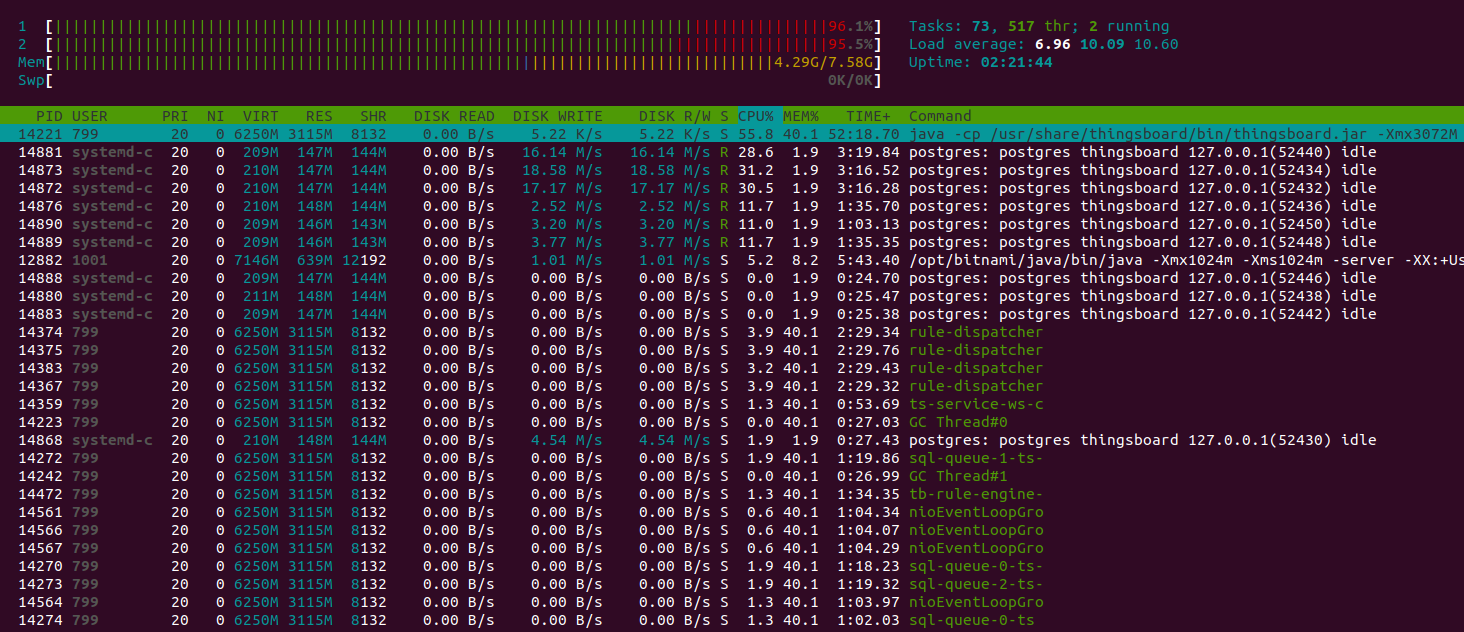
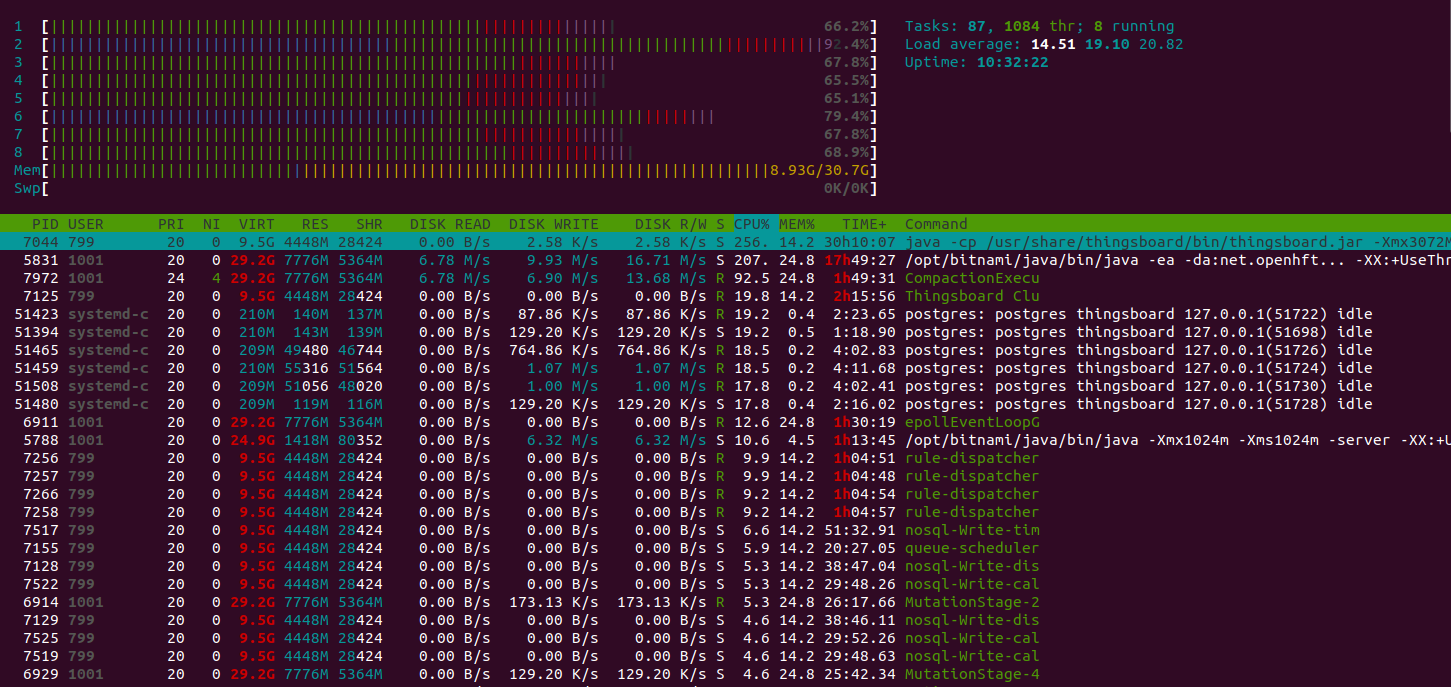
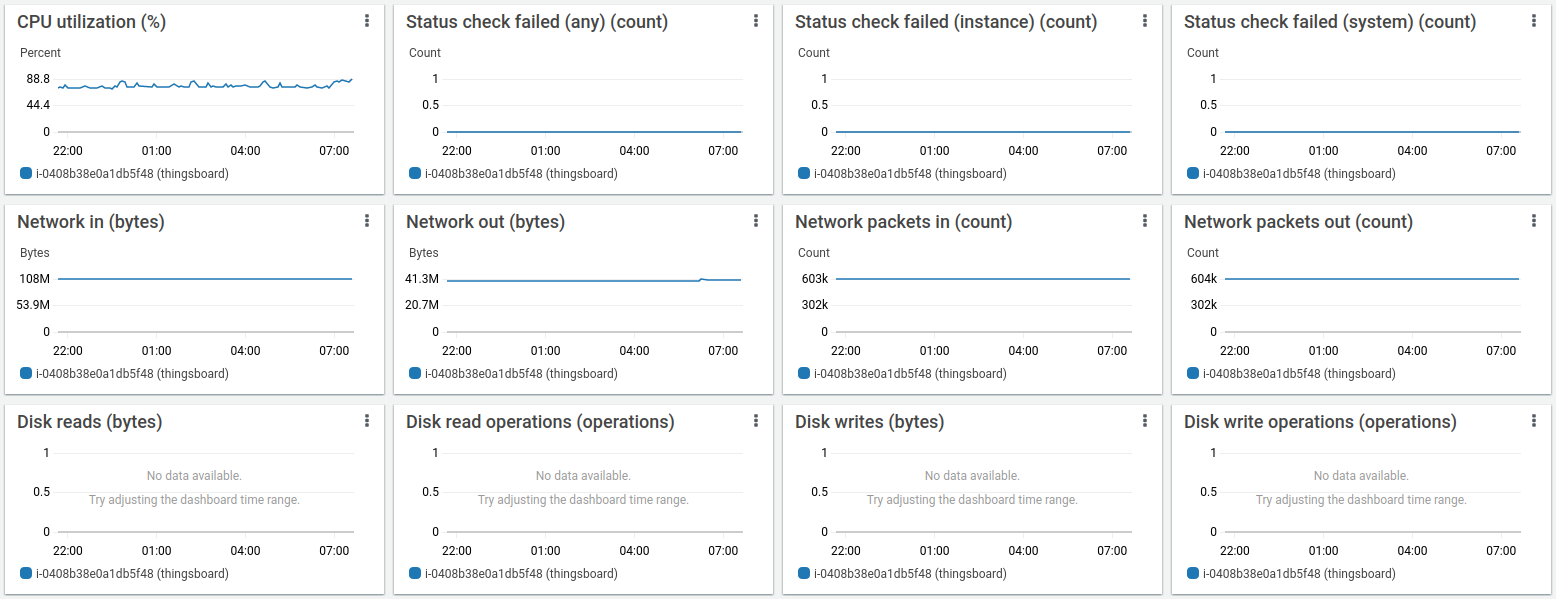
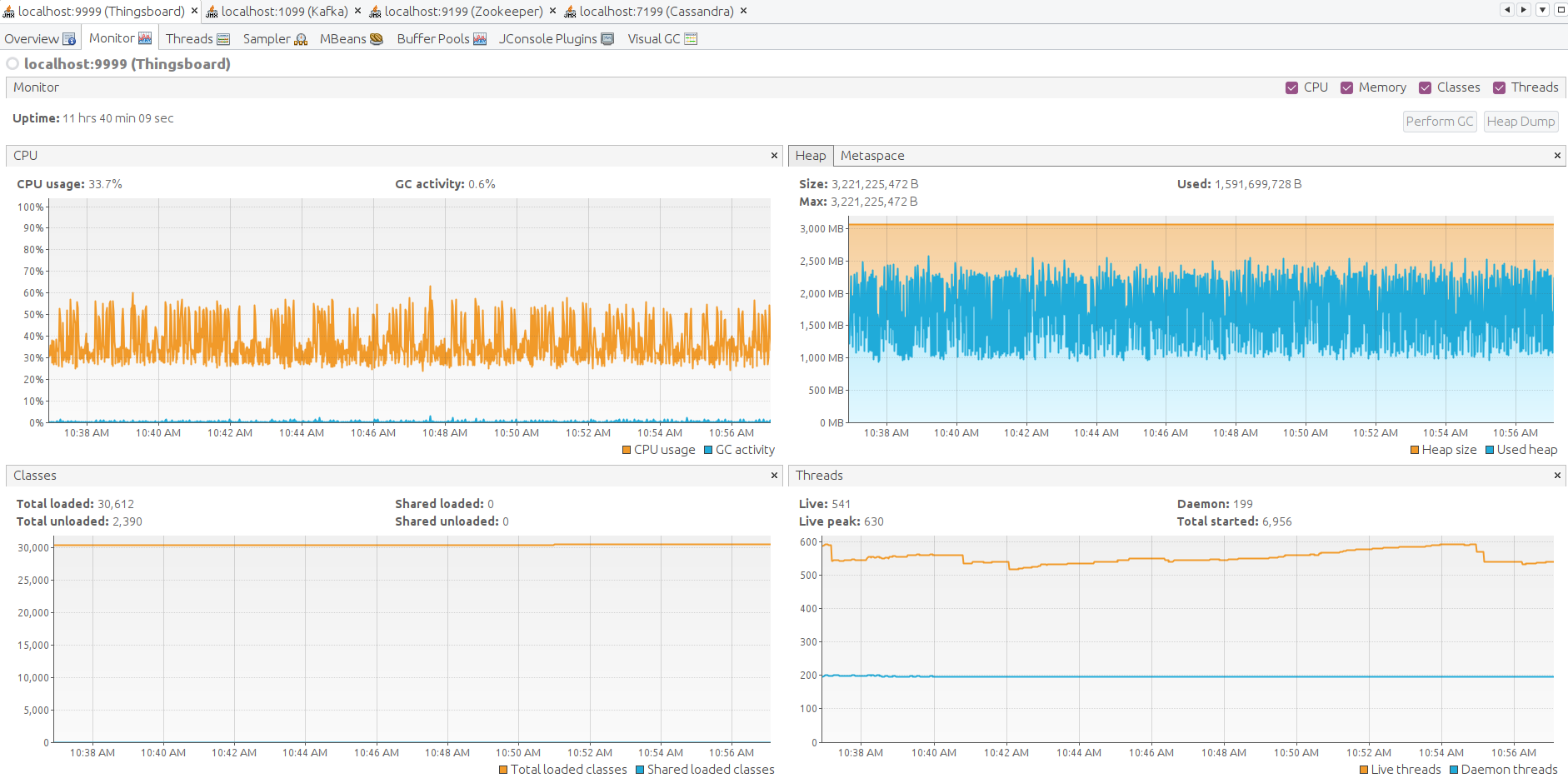
Htop shows the system is working normally and have a plenty of resources to handle another jobs. Memory consumption is about 9GiB, other memory is the system file cache. The instance with 16GiB is more that enough to run that load.
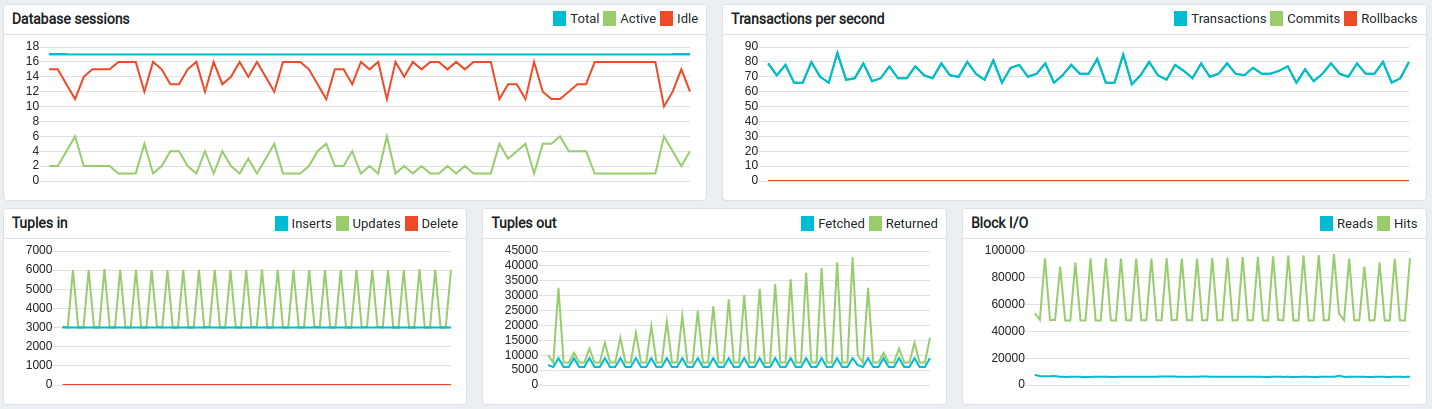
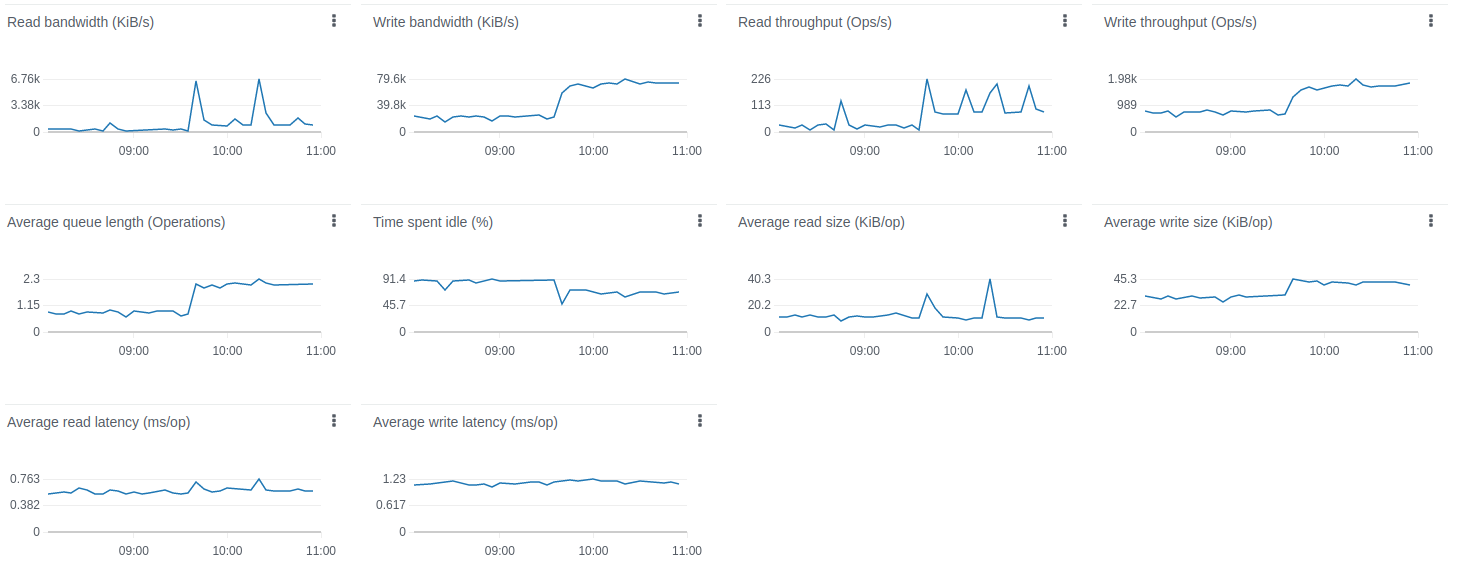
PostgreSQL is causing CPU load due to quite intensive updates of the “ts_kv_latest” table whis is storing the latest values of time-series data for each device. The pace of updates reach the peak value at about 60k updates/sec.
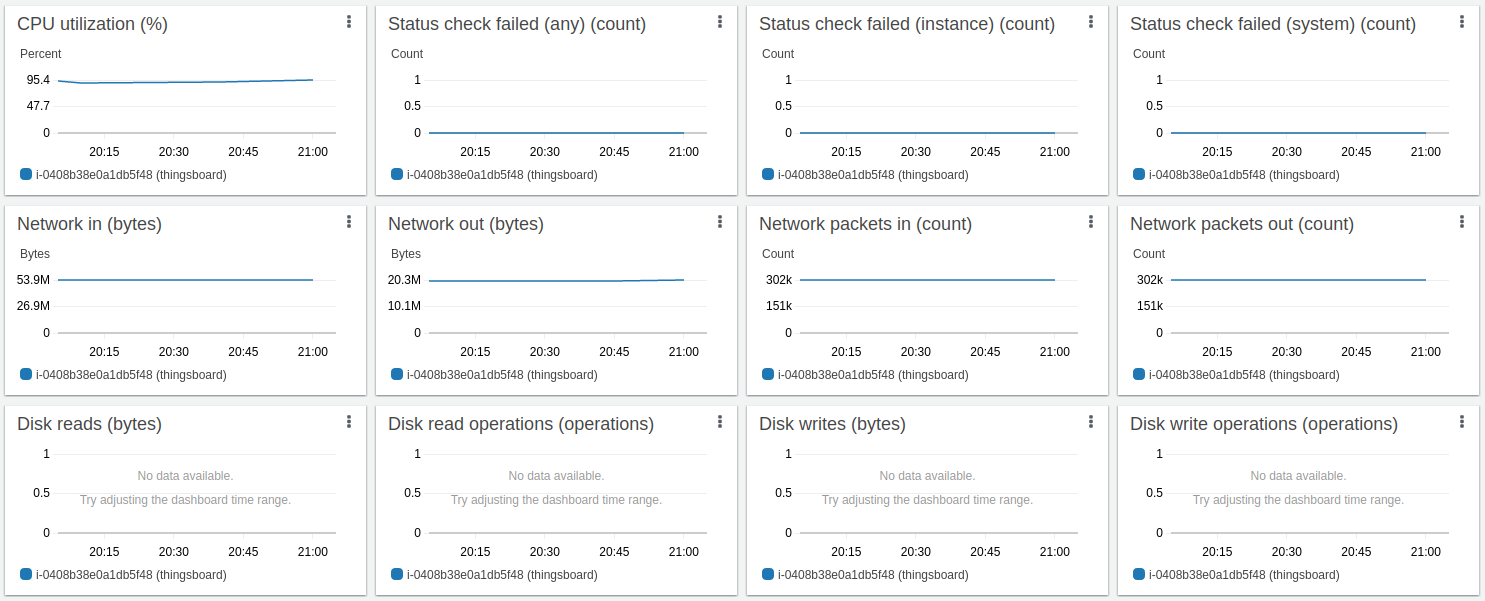
AWS instance monitoring shows about 75% average CPU load with a peak up to 88%
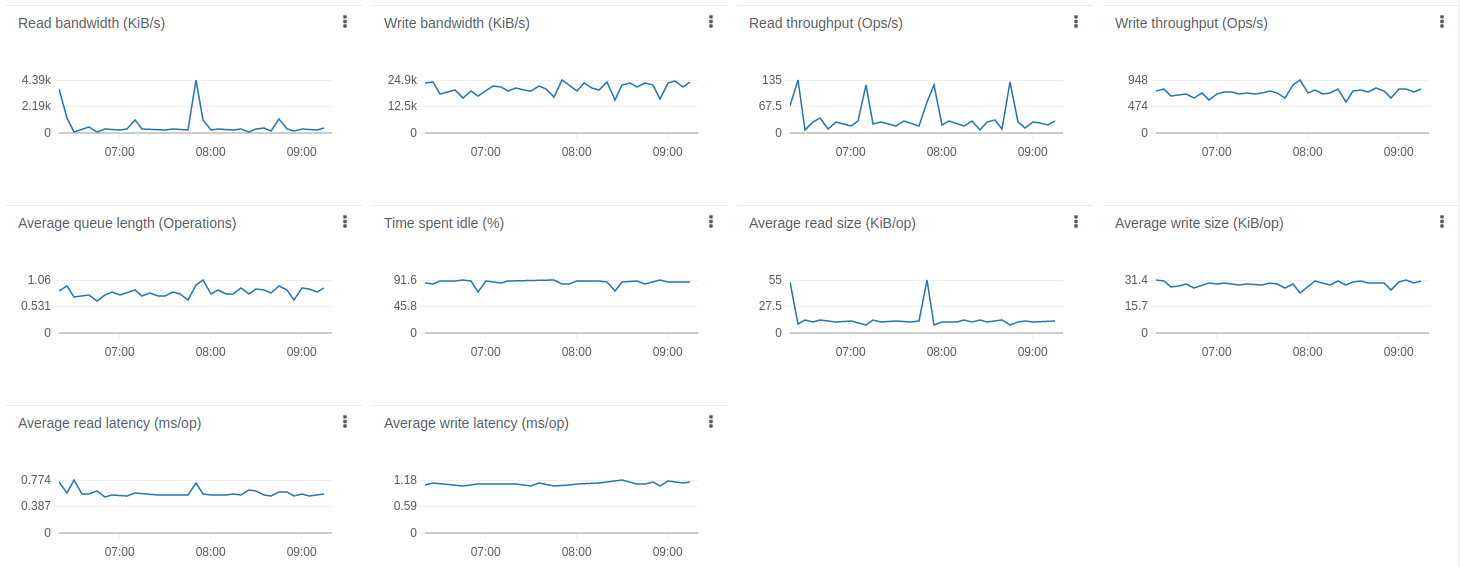
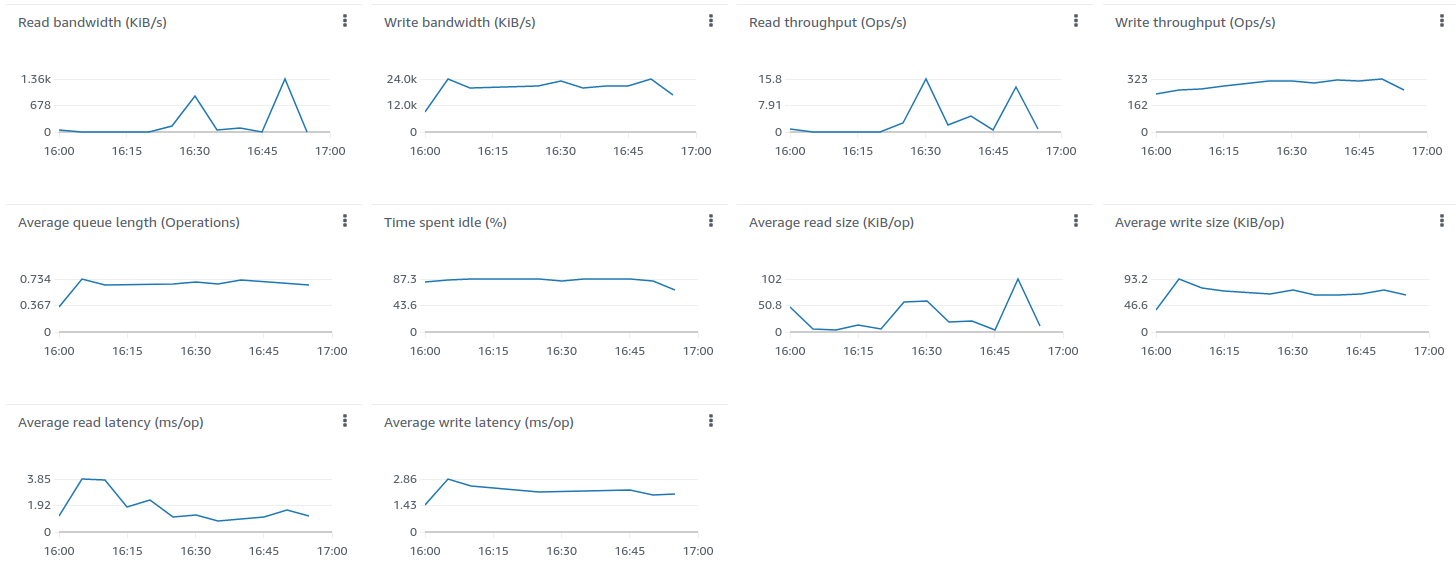
The disk load is extremely low compare to the PostgreSQL only deployment
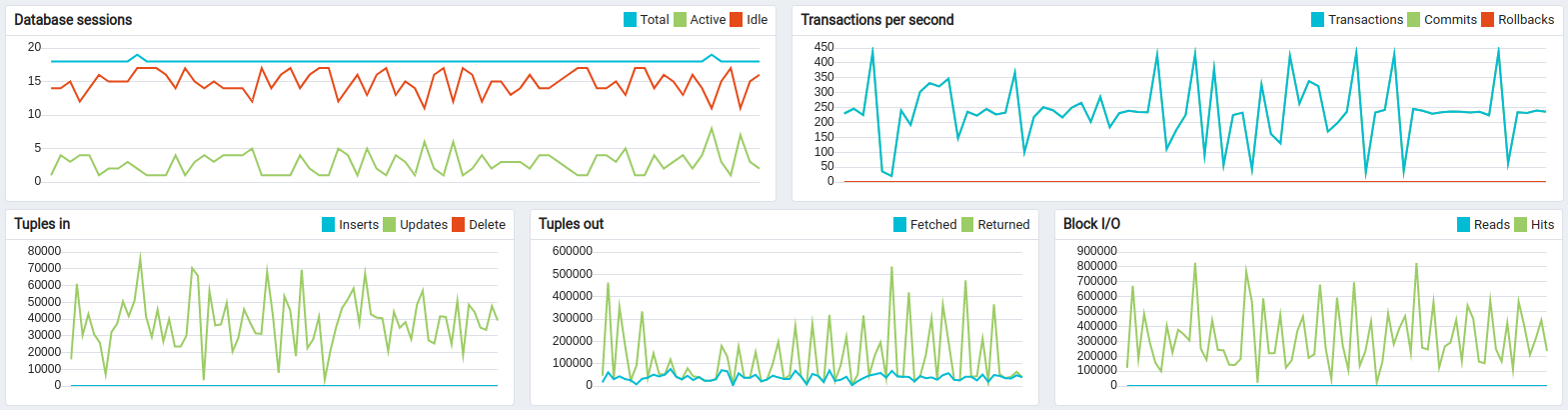
Cassandra’s disk size and IOPS usage is quite low (cheaper) compare to PostgreSQL-only deployments.
For 1.15B data points Cassandra uses 33GiB of disk space (29 GiB per 1B data points). As reminder, PostgreSQL takes about 161 GiB to persist 1.06B data points (152 GiB per 1B data points). It is more than x5 times (152 / 29) cheaper than PostgreSQL disk consumption!

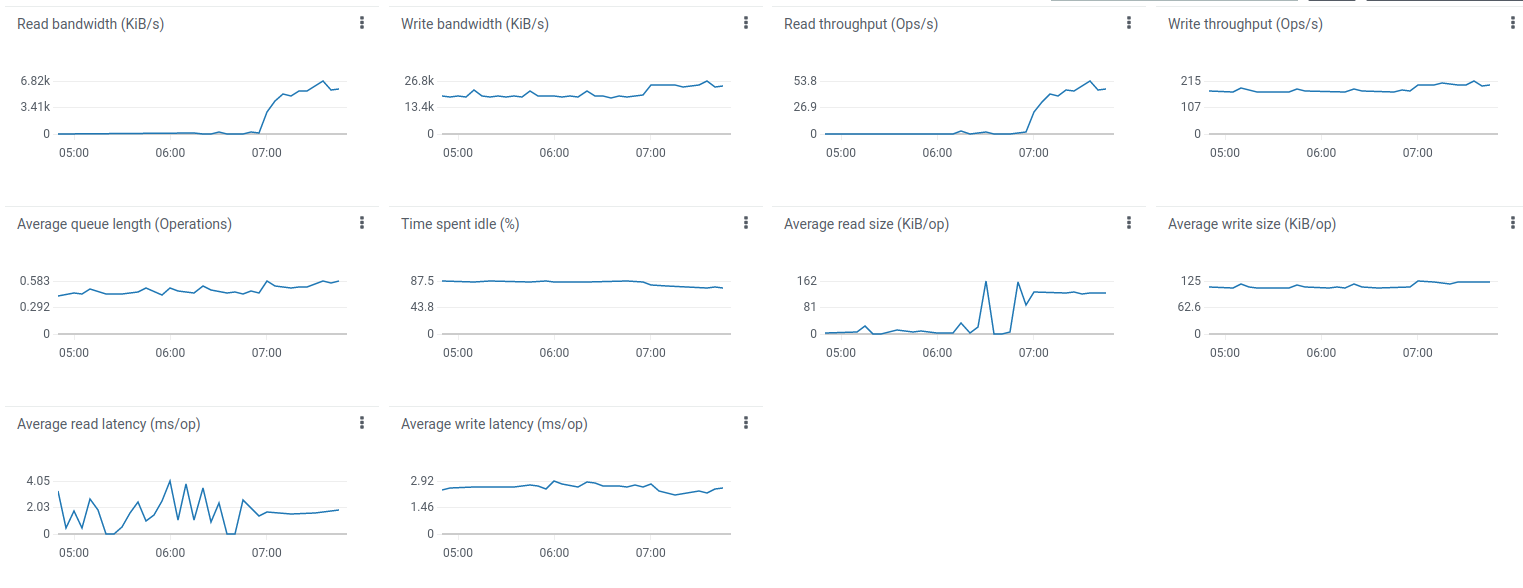
Finally, let’s check the JVM state on each Thingsboard, Zookeeper, Kafka and Cassandra Let’s forward JMX port with SSH to connect and monitor all Java applications presented.
1
ssh -L 9999:127.0.0.1:9999 -L 1099:127.0.0.1:1099 -L 9199:127.0.0.1:9199 -L 7199:127.0.0.1:7199 thingsboard
Open VisualVM, add the local applications, open it and let the data being gathered for a few minutes.
Here the JMX monitoring for ThingsBoard, Kafka, Zookeeper, Cassandra. The system is stable.
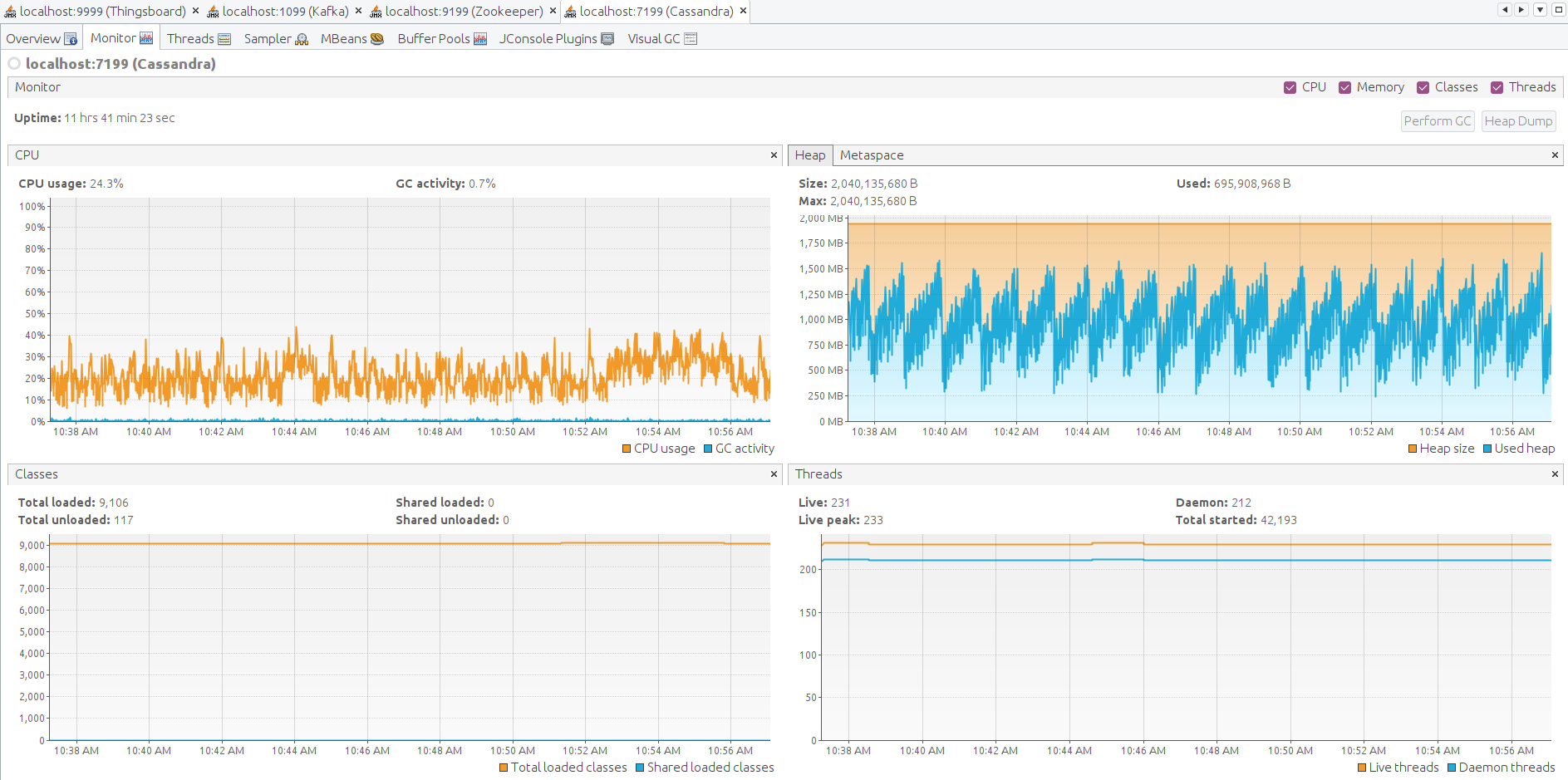
Lessons learned
Cassandra is essential for massive telemetry flow. Peak load is handled with Kafka queue. Bundling Kafka + PostgreSQL + Cassandra is a top ThingsBoard deployment.
Cassandra requires more CPU resources, but 5 time less disk space. It also dramatically reduces the IOPS load. CPU load is 75% on average. This is a good setup with average load 10k msg/sec, 30k data point/sec.
Cassandra can handle x2-x3 more load (compare to PostgreSQL only) with a single instance deployment and able to scale up horizontally by adding a new nodes to the Cassandra cluster.
It is a good idea to start with Cassandra from the very beginning of your ThingsBoard instance and maintain the same stack for the entire project lifetime.
For the lower message rate, you can fit the Cassandra deployment to a much smaller instance adjusting the heap size limits.
System can be scaled up vertically up to 50-100%. For significant horizontal scaling, please, consider to set up a ThingsBoard cluster.
How to reproduce the test:
Setup the ThingsBoard instance on AWS EC2
Use the Docker Compose file listed below to setup the AWS EC2 instance based on the instruction.
Here the docker-compose with ThingsBoard + Postgresql + Zookeeper + Kafka + Cassandra
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
version: '3.0'
services:
cassandra:
image: bitnamilegacy/cassandra:4.0
network_mode: "host"
restart: "always"
volumes:
- cassandra:/bitnami
environment:
CASSANDRA_CLUSTER_NAME: "ThingsBoard Cluster"
HEAP_NEWSIZE: "1024M"
MAX_HEAP_SIZE: "2048M"
JVM_EXTRA_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=7199 -Dcom.sun.management.jmxremote.rmi.port=7199 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
zookeeper:
image: bitnamilegacy/zookeeper:3.7
network_mode: "host"
restart: "always"
volumes:
- zookeeper:/bitnami
environment:
ALLOW_ANONYMOUS_LOGIN: "yes"
ZOO_ENABLE_ADMIN_SERVER: "no"
JVMFLAGS: "-Xmx128m -Xms128m -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9199 -Dcom.sun.management.jmxremote.rmi.port=9199 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
kafka:
image: bitnamilegacy/kafka:3
network_mode: "host"
restart: "always"
volumes:
- kafka:/bitnami
environment:
KAFKA_CFG_ZOOKEEPER_CONNECT: "localhost:2181"
ALLOW_PLAINTEXT_LISTENER: "yes"
KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.rmi.port=1099 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
JMX_PORT: "1099"
depends_on:
- zookeeper
postgres:
image: "postgres:14"
network_mode: "host"
restart: "always"
volumes:
- postgres:/var/lib/postgresql/data
environment:
POSTGRES_DB: "thingsboard"
POSTGRES_PASSWORD: "postgres"
tb:
depends_on:
- postgres
- kafka
- cassandra
image: "thingsboard/tb"
network_mode: "host"
restart: "always"
volumes:
- thingsboard-data:/data
- thingsboard-logs:/var/log/thingsboard
environment:
DATABASE_TS_TYPE: "cassandra"
DATABASE_TS_LATEST_TYPE: "sql"
#Cassandra
CASSANDRA_CLUSTER_NAME: "ThingsBoard Cluster"
CASSANDRA_LOCAL_DATACENTER: "datacenter1"
CASSANDRA_KEYSPACE_NAME: "thingsboard"
CASSANDRA_URL: "127.0.0.1:9042"
CASSANDRA_USE_CREDENTIALS: "true"
CASSANDRA_USERNAME: "cassandra"
CASSANDRA_PASSWORD: "cassandra"
CASSANDRA_QUERY_BUFFER_SIZE: "100000"
CASSANDRA_QUERY_CONCURRENT_LIMIT: "1000"
CASSANDRA_QUERY_POLL_MS: "10"
#Kafka
TB_QUEUE_TYPE: "kafka"
TB_KAFKA_BATCH_SIZE: "65536" # default is 16384 - it helps to produce messages much efficiently
TB_KAFKA_LINGER_MS: "5" # default is 1
TB_QUEUE_KAFKA_MAX_POLL_RECORDS: "2048" # default is 8192
TB_SERVICE_ID: "tb-node-0"
HTTP_BIND_PORT: "8080"
TB_QUEUE_RE_MAIN_PACK_PROCESSING_TIMEOUT_MS: "30000"
# Postgres connection
SPRING_DATASOURCE_URL: "jdbc:postgresql://localhost:5432/thingsboard"
SPRING_DATASOURCE_USERNAME: "postgres"
SPRING_DATASOURCE_PASSWORD: "postgres"
# Cache specs
CACHE_SPECS_DEVICES_MAX_SIZE: "123456" # default is 10000
CACHE_SPECS_DEVICE_CREDENTIALS_MAX_SIZE: "123456" # default is 10000
CACHE_SPECS_SESSIONS_MAX_SIZE: "123456" # default is 10000
# Java options for 8G instance and JMX enabled
JAVA_OPTS: " -Xmx3072M -Xms3072M -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.rmi.port=9999 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
volumes: # to persist data between container restarts or being recreated
cassandra:
kafka:
zookeeper:
postgres:
thingsboard-data:
thingsboard-logs:
Launch performance test tool
Use the Docker command listed below to launch the performance test tool based on the instruction.
1
2
3
4
5
6
7
8
9
10
11
# Put your ThingsBoard private IP address here, assuming both ThingsBoard and performance tests EC2 instances are in same VPC.
export TB_INTERNAL_IP=172.31.16.229
docker run -it --rm --network host --name tb-perf-test \
--env REST_URL=http://$TB_INTERNAL_IP:8080 \
--env MQTT_HOST=$TB_INTERNAL_IP \
--env DEVICE_END_IDX=25000 \
--env MESSAGES_PER_SECOND=10000 \
--env ALARMS_PER_SECOND=50 \
--env DURATION_IN_SECONDS=86400 \
--env DEVICE_CREATE_ON_START=true \
thingsboard/tb-ce-performance-test:3.3.3
Scenario D
Load configuration:
- 100 000 devices;
- 5000 msg/sec over MQTT, each mqtt message contains 3 data points resulting in 15000 data points/sec;
- PostgreSQL database to store entities, attributes and latest values of time-series data;
- Cassandra database to store time-series data;
- Kafka queue.
Instance: AWS m6a.2xlarge (8 vCPUs AMD EPYC 3rd, 32 GiB, EBS GP3)
Estimated cost: 167$ EC2 m6a.2xlarge + 24$ EBS GP3 300GB = 191$/month.
Test runs 24 hour and here the results:
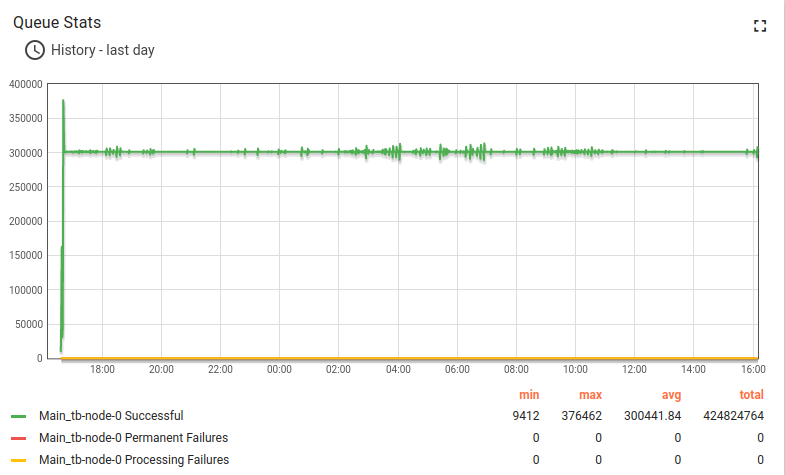
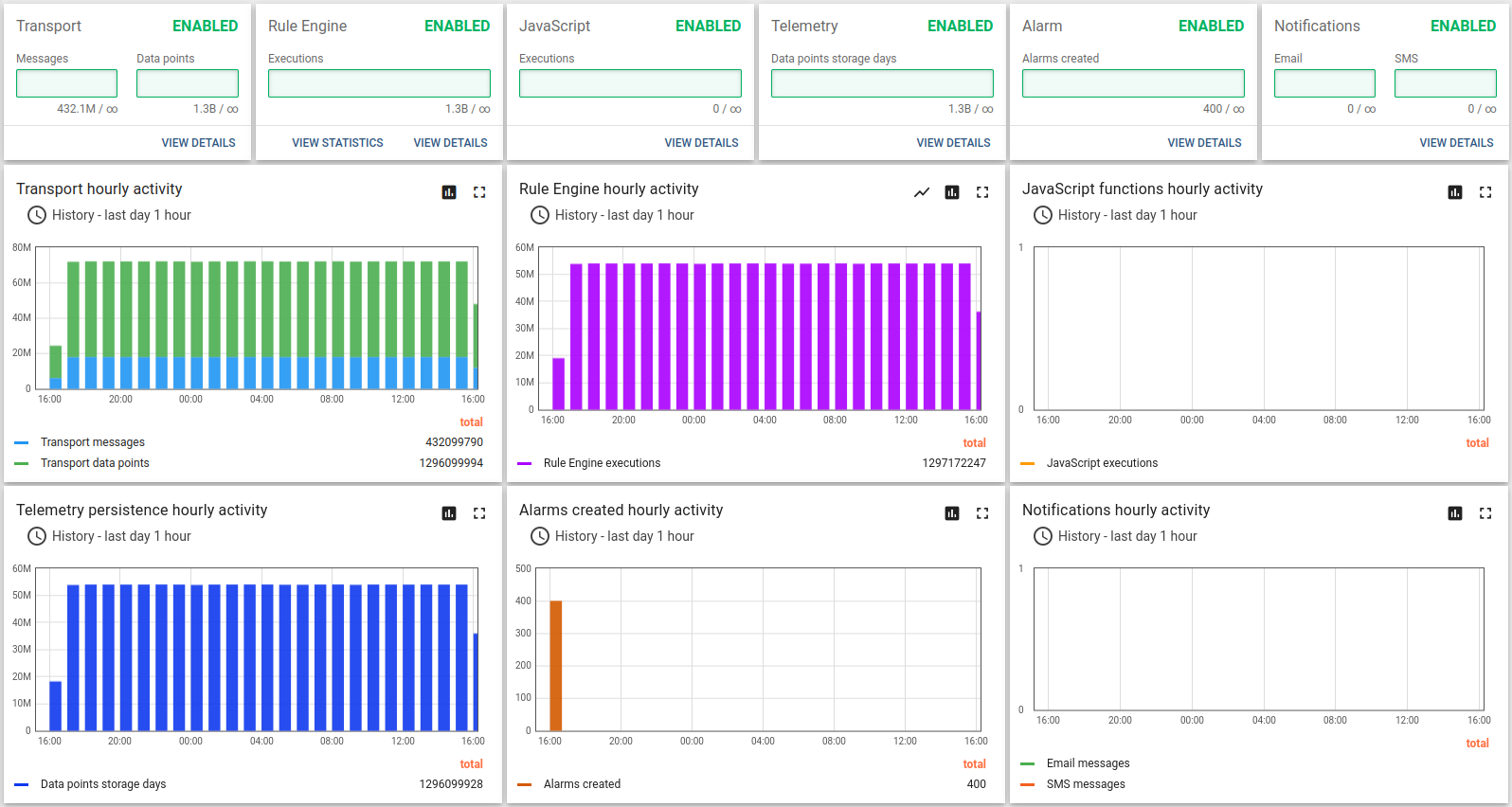
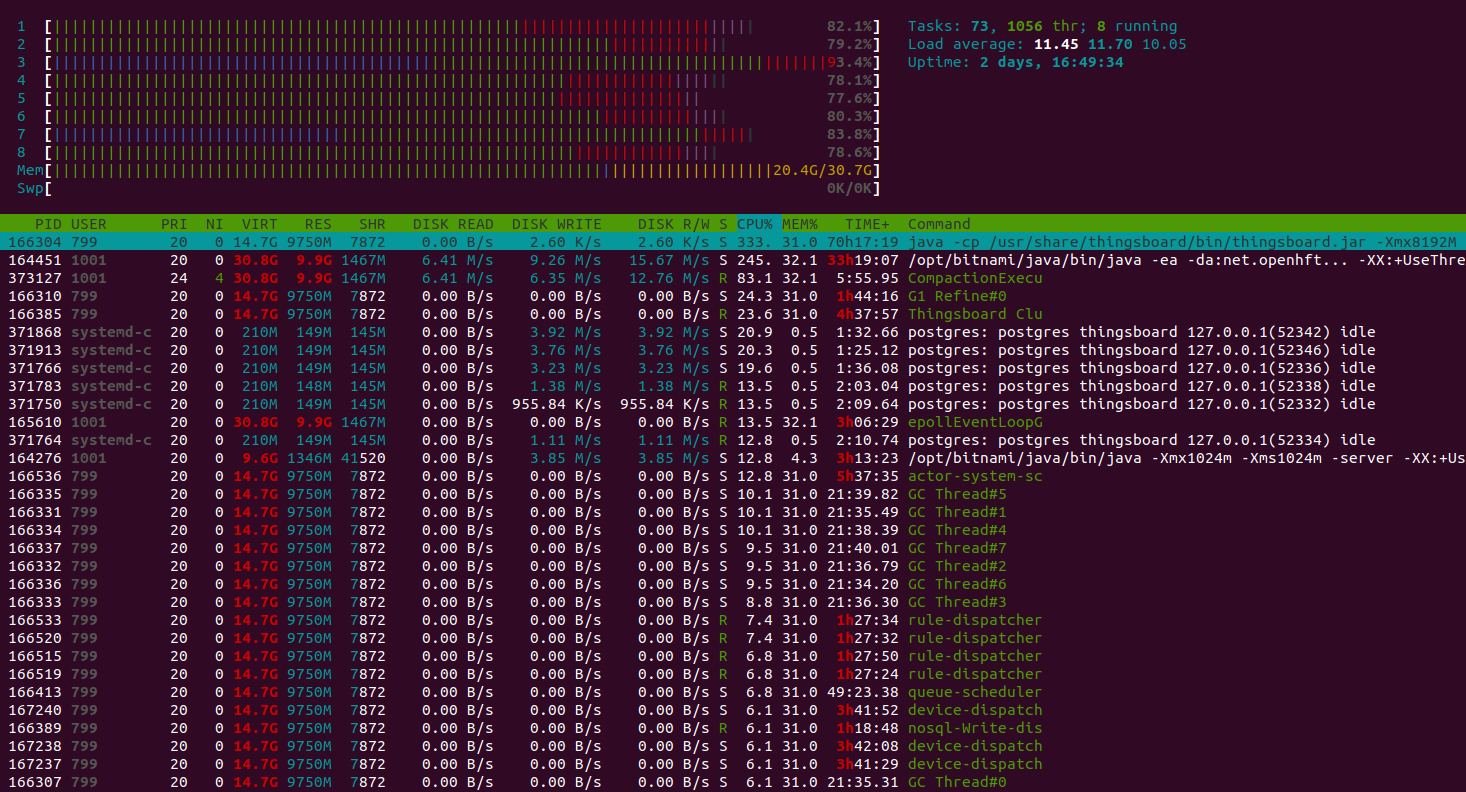
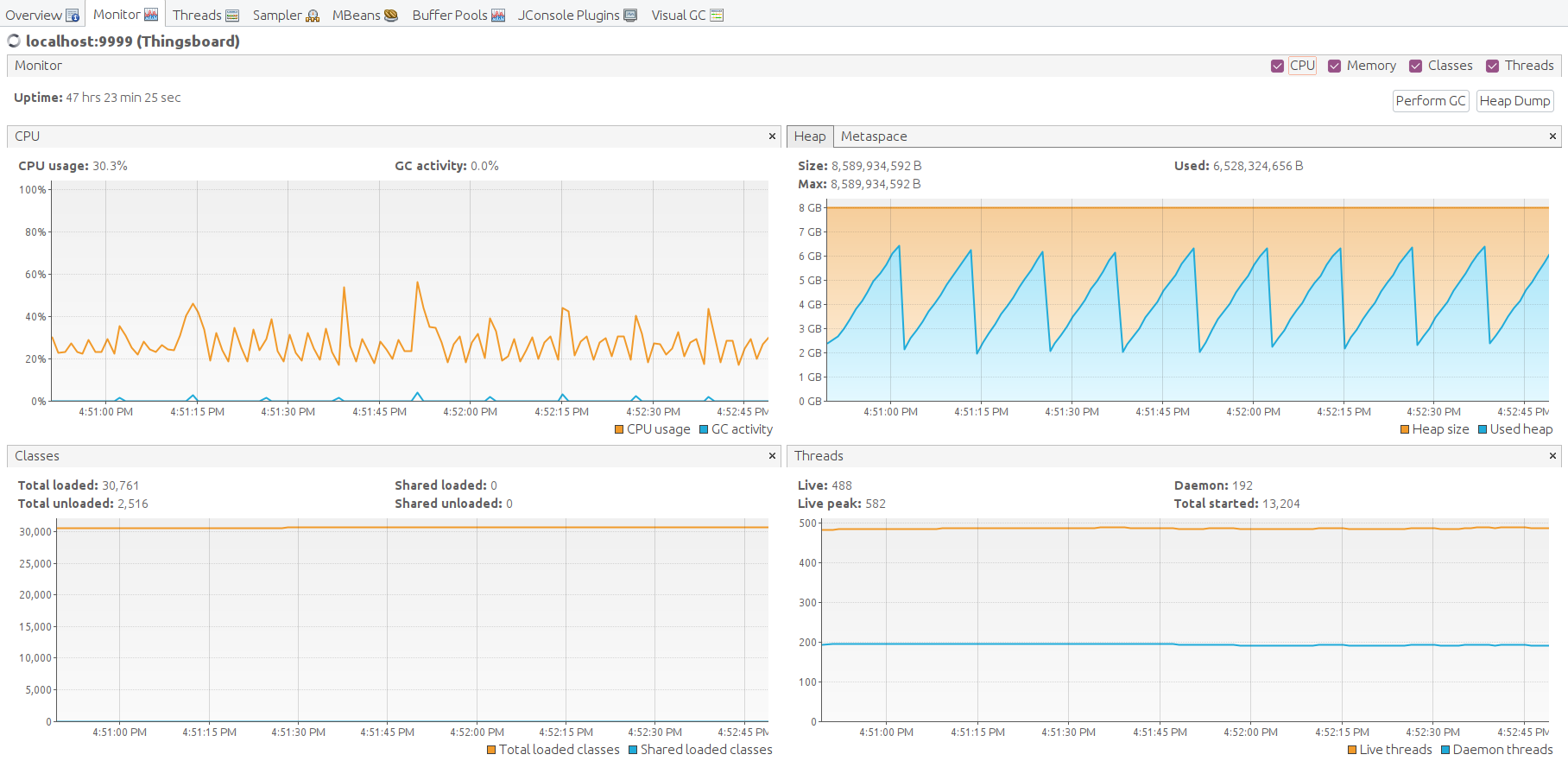
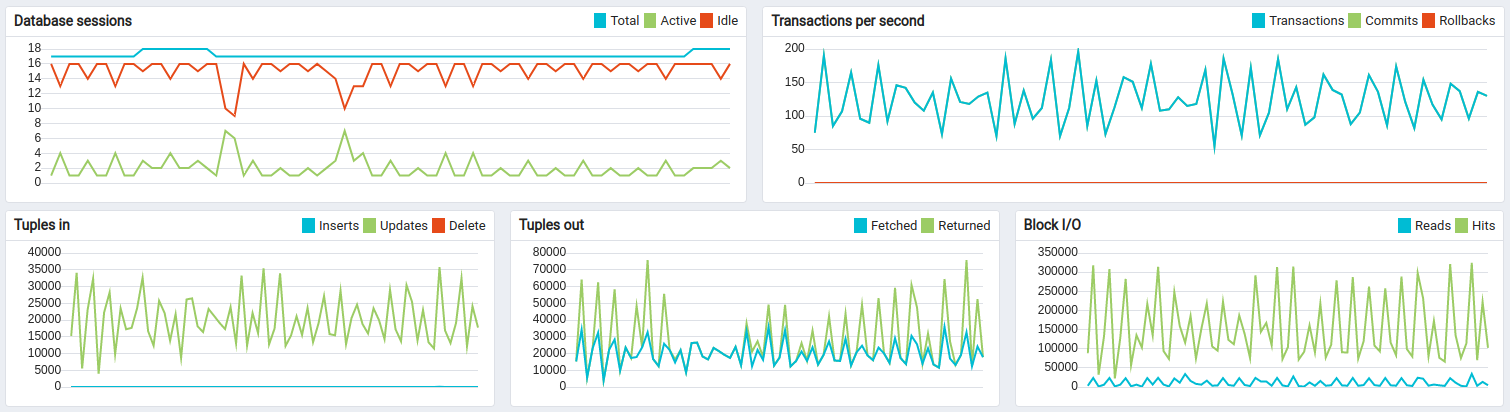
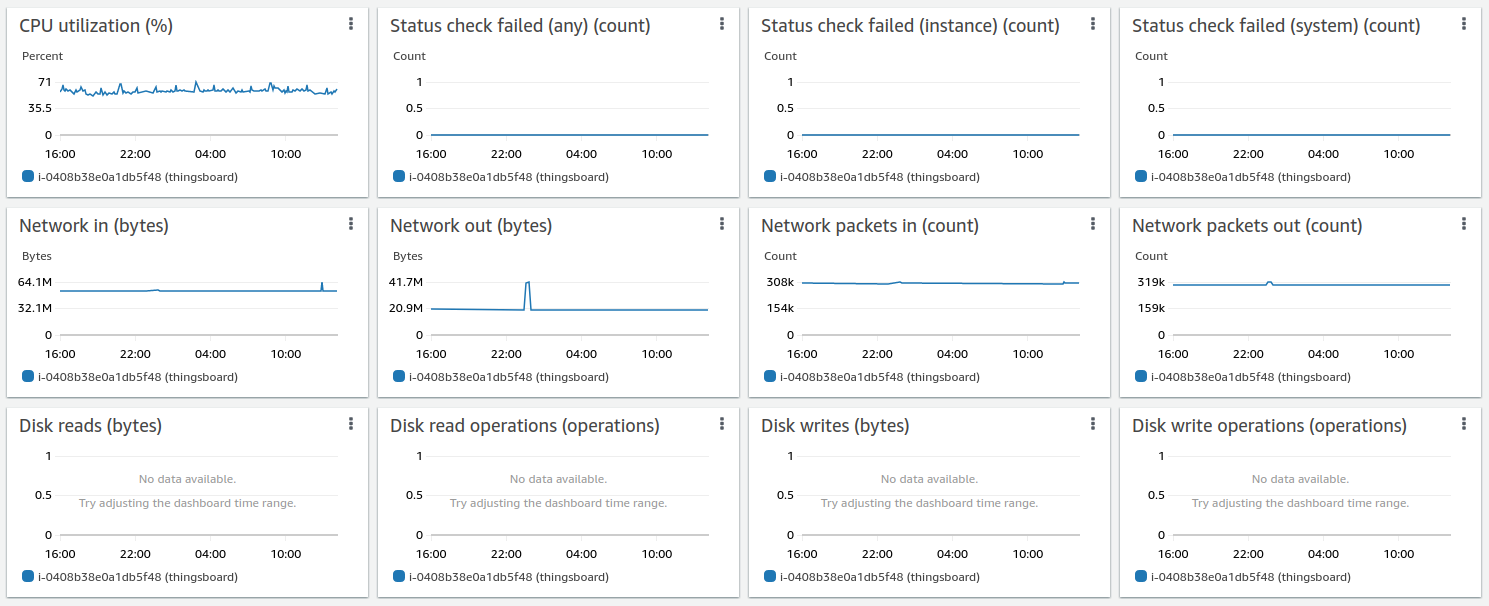
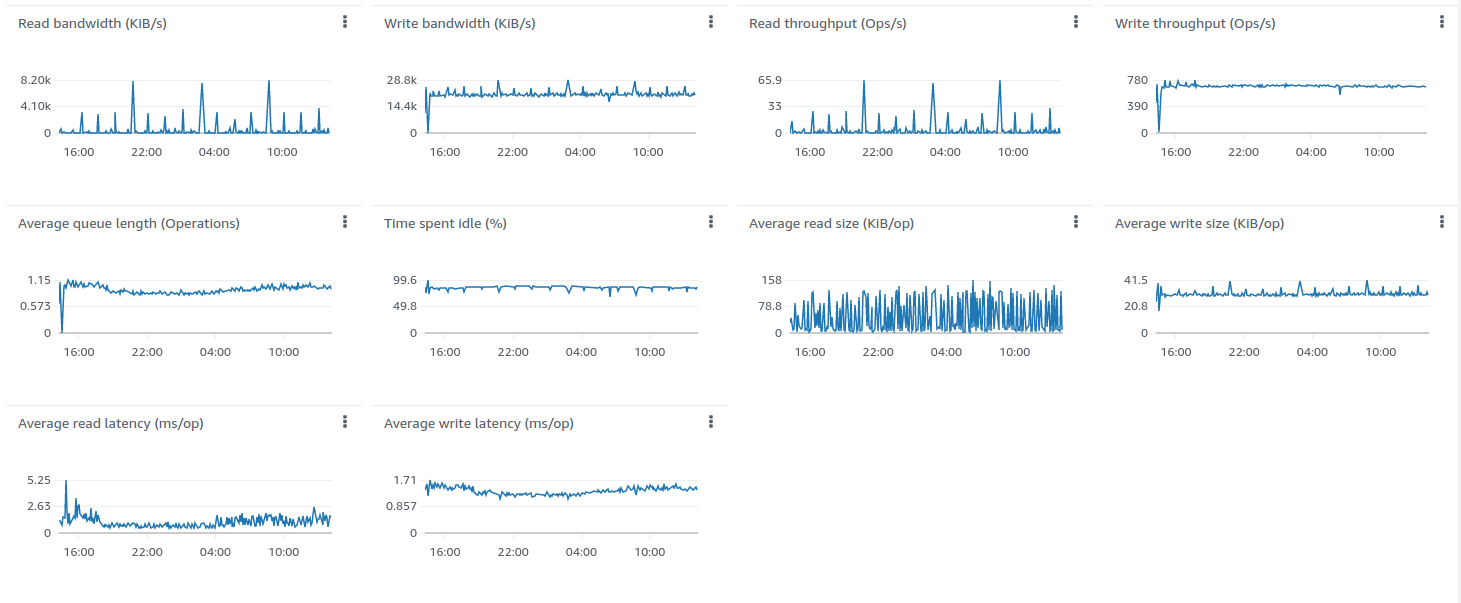
Lessons learned
In addition to conclusions we made for Scenario C, we observe stability of a single ThingsBoard instance handling 100K parallel MQTT connections. We observe that memory consumption increased from 1.5 GB for 25K devices to 6.5 for 100K devices. We may roughly calculate that one device/connection consumes 66KB of memory. We will work to reduce this number 10 times in the next release.
How to reproduce the test:
Setup the ThingsBoard instance on AWS EC2
Use the Docker Compose file listed below to setup the AWS EC2 instance based on the instruction.
Here the docker-compose with ThingsBoard + Postgresql + Zookeeper + Kafka + Cassandra
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
version: '3.0'
services:
cassandra:
image: bitnamilegacy/cassandra:4.0
network_mode: "host"
restart: "always"
volumes:
- cassandra:/bitnami
environment:
CASSANDRA_CLUSTER_NAME: "ThingsBoard Cluster"
HEAP_NEWSIZE: "4096M"
MAX_HEAP_SIZE: "8192M"
JVM_EXTRA_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=7199 -Dcom.sun.management.jmxremote.rmi.port=7199 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
zookeeper:
image: bitnamilegacy/zookeeper:3.7
network_mode: "host"
restart: "always"
volumes:
- zookeeper:/bitnami
environment:
ALLOW_ANONYMOUS_LOGIN: "yes"
ZOO_ENABLE_ADMIN_SERVER: "no"
JVMFLAGS: "-Xmx128m -Xms128m -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9199 -Dcom.sun.management.jmxremote.rmi.port=9199 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
kafka:
image: bitnamilegacy/kafka:3
network_mode: "host"
restart: "always"
volumes:
- kafka:/bitnami
environment:
KAFKA_CFG_ZOOKEEPER_CONNECT: "localhost:2181"
ALLOW_PLAINTEXT_LISTENER: "yes"
KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.rmi.port=1099 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
JMX_PORT: "1099"
depends_on:
- zookeeper
postgres:
image: "postgres:14"
network_mode: "host"
restart: "always"
volumes:
- postgres:/var/lib/postgresql/data
environment:
POSTGRES_DB: "thingsboard"
POSTGRES_PASSWORD: "postgres"
tb:
depends_on:
- postgres
- kafka
- cassandra
image: "thingsboard/tb"
network_mode: "host"
restart: "always"
volumes:
- thingsboard-data:/data
- thingsboard-logs:/var/log/thingsboard
environment:
DATABASE_TS_TYPE: "cassandra"
DATABASE_TS_LATEST_TYPE: "sql"
#Cassandra
CASSANDRA_CLUSTER_NAME: "ThingsBoard Cluster"
CASSANDRA_LOCAL_DATACENTER: "datacenter1"
CASSANDRA_KEYSPACE_NAME: "thingsboard"
CASSANDRA_URL: "127.0.0.1:9042"
CASSANDRA_USE_CREDENTIALS: "true"
CASSANDRA_USERNAME: "cassandra"
CASSANDRA_PASSWORD: "cassandra"
CASSANDRA_QUERY_BUFFER_SIZE: "200000"
CASSANDRA_QUERY_CONCURRENT_LIMIT: "1000"
CASSANDRA_QUERY_POLL_MS: "5"
#Kafka
TB_QUEUE_TYPE: "kafka"
TB_KAFKA_BATCH_SIZE: "65536" # default is 16384 - it helps to produce messages much efficiently
TB_KAFKA_LINGER_MS: "5" # default is 1
TB_QUEUE_KAFKA_MAX_POLL_RECORDS: "2048" # default is 8192
TB_SERVICE_ID: "tb-node-0"
HTTP_BIND_PORT: "8080"
TB_QUEUE_RE_MAIN_PACK_PROCESSING_TIMEOUT_MS: "30000"
# Postgres connection
SPRING_DATASOURCE_URL: "jdbc:postgresql://localhost:5432/thingsboard"
SPRING_DATASOURCE_USERNAME: "postgres"
SPRING_DATASOURCE_PASSWORD: "postgres"
# Cache specs
CACHE_SPECS_DEVICES_MAX_SIZE: "512000" # default is 10000
CACHE_SPECS_DEVICE_CREDENTIALS_MAX_SIZE: "512000" # default is 10000
CACHE_SPECS_SESSIONS_MAX_SIZE: "512000" # default is 10000
TS_KV_PARTITIONS_MAX_CACHE_SIZE: "3000000" # default is 100000
# Device state service
DEFAULT_INACTIVITY_TIMEOUT: "1800" # defailt is 600 (10min)
DEFAULT_STATE_CHECK_INTERVAL: "600" # default is 60 (1min)
# Java options for 16G instance and JMX enabled
JAVA_OPTS: " -Xmx8192M -Xms8192M -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.rmi.port=9999 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
ulimits:
nofile:
soft: 1048576
hard: 1048576
volumes: # to persist data between container restarts or being recreated
cassandra:
kafka:
zookeeper:
postgres:
thingsboard-data:
thingsboard-logs:
Launch performance test tool on two nodes
Use the Docker command listed below to launch the performance test tool based on the instruction.
We need at least two performance-test instances to produce 100k simultaneous connections because each test instance may create up to 65535 simultaneous connections to a particular external server. By default, Ubuntu Linux allows you to spin up a 28232 outgoing connection providing a local port range from 32768 to 60999. So, we need to increase the IP local port range on a performance test instance that setup many outgoing connections. Now we can open up to 64511 IP ports.
1
2
3
4
5
6
7
8
9
10
ssh pt
cat /proc/sys/net/ipv4/ip_local_port_range
#32768 60999
echo "net.ipv4.ip_local_port_range = 1024 65535" | sudo tee -a /etc/sysctl.conf
sudo -s sysctl -p
cat /proc/sys/net/ipv4/ip_local_port_range
#1024 65535
ulimit -n 1048576
sudo sysctl -a | grep conntrack_max
sudo sysctl -w net.netfilter.nf_conntrack_max=1048576
Here is the run script for the first node.
1
2
3
4
5
6
7
8
9
10
11
12
# Put your ThingsBoard private IP address here, assuming both ThingsBoard and performance tests EC2 instances are in same VPC.
export TB_INTERNAL_IP=172.31.16.229
docker run -it --rm --network host --name tb-perf-test \
--env REST_URL=http://$TB_INTERNAL_IP:8080 \
--env MQTT_HOST=$TB_INTERNAL_IP \
--env DEVICE_START_IDX=0 \
--env DEVICE_END_IDX=50000 \
--env MESSAGES_PER_SECOND=2500 \
--env ALARMS_PER_SECOND=10 \
--env DURATION_IN_SECONDS=86400 \
--env DEVICE_CREATE_ON_START=true \
thingsboard/tb-ce-performance-test:3.3.3
Here is the run script for the second node. Note the DEVICE_START_IDX and DEVICE_END_IDX values are different from the one we used on the first node.
1
2
3
4
5
6
7
8
9
10
11
12
# Put your ThingsBoard private IP address here, assuming both ThingsBoard and performance tests EC2 instances are in same VPC.
export TB_INTERNAL_IP=172.31.16.229
docker run -it --rm --network host --name tb-perf-test \
--env REST_URL=http://$TB_INTERNAL_IP:8080 \
--env MQTT_HOST=$TB_INTERNAL_IP \
--env DEVICE_START_IDX=50000 \
--env DEVICE_END_IDX=100000 \
--env MESSAGES_PER_SECOND=2500 \
--env ALARMS_PER_SECOND=10 \
--env DURATION_IN_SECONDS=86400 \
--env DEVICE_CREATE_ON_START=true \
thingsboard/tb-ce-performance-test:3.3.3
Scenario E
Load configuration:
- 100 000 devices;
- 10 000 msg/sec over MQTT, each mqtt message contains 3 data points resulting in 30 000 data points/sec;
- PostgreSQL database to store entities, attributes and latest values of time-series data;
- Cassandra database to store time-series data;
- Kafka queue.
Instance: AWS m6a.2xlarge (8 vCPUs AMD EPYC 3rd, 32 GiB, EBS GP3)
Estimated cost: 167$ EC2 m6a.2xlarge + 24$ EBS GP3 300GB = 191$/month.
** Necessary performance tuning **
With the msg rate is 10k/sec for 100k devices system can handle about 9k/sec in average. The CPU load is 90%, so we face the PostgreSQL performance bottleneck. It is too many attribute updates with different keys. The attribute ‘lastActivityTime’ in trying to update on each message received from device. With 5k devices it is no problem, but with 100k devices transaction became much slower. As the next step we are going to write device state to the Cassandra.
Great improvement for performance is to persist device state to Cassandra telemetry using the following env variable:
1
PERSIST_STATE_TO_TELEMETRY: "true" # Persist device state to the Cassandra. Default is false (Postgres, as device server_scope attributes)
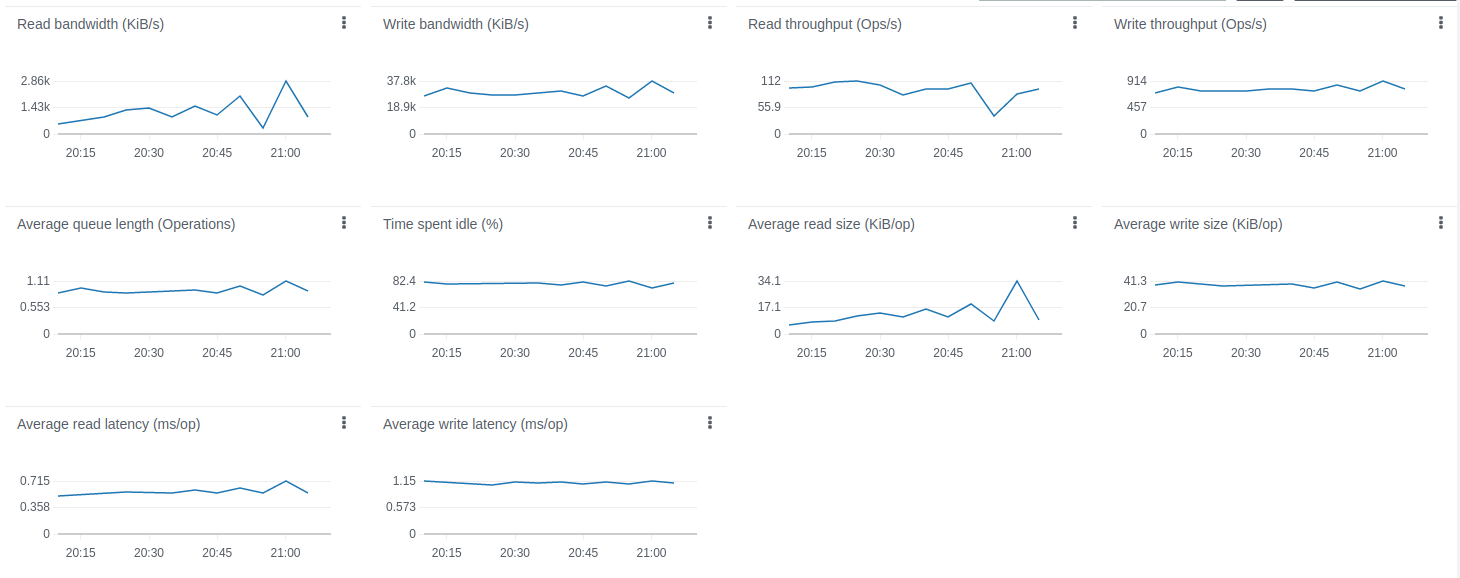
Test results looks fine:
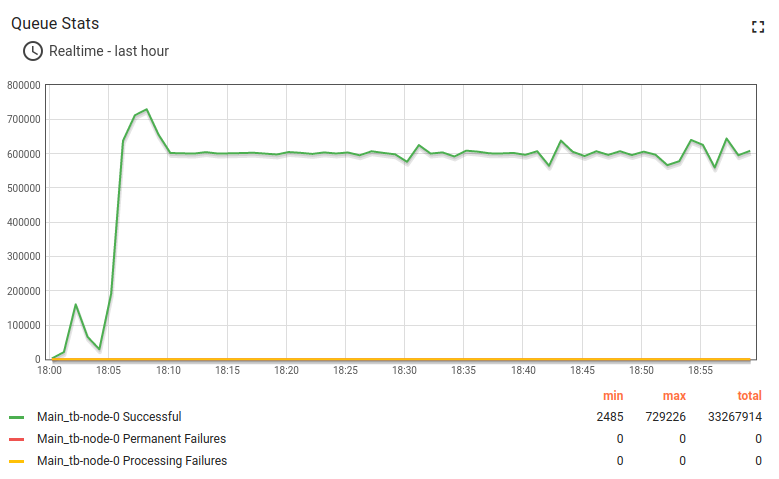
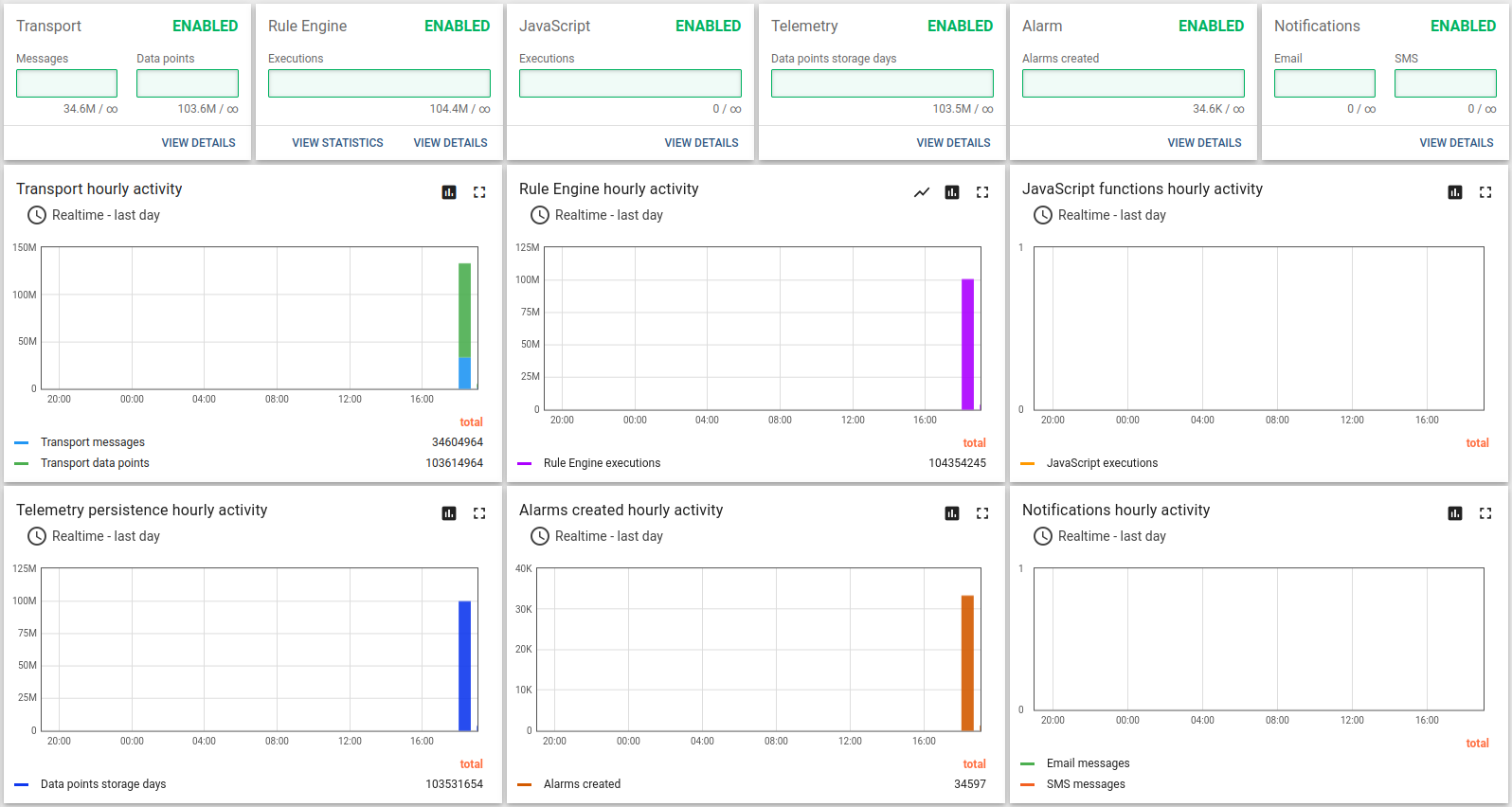
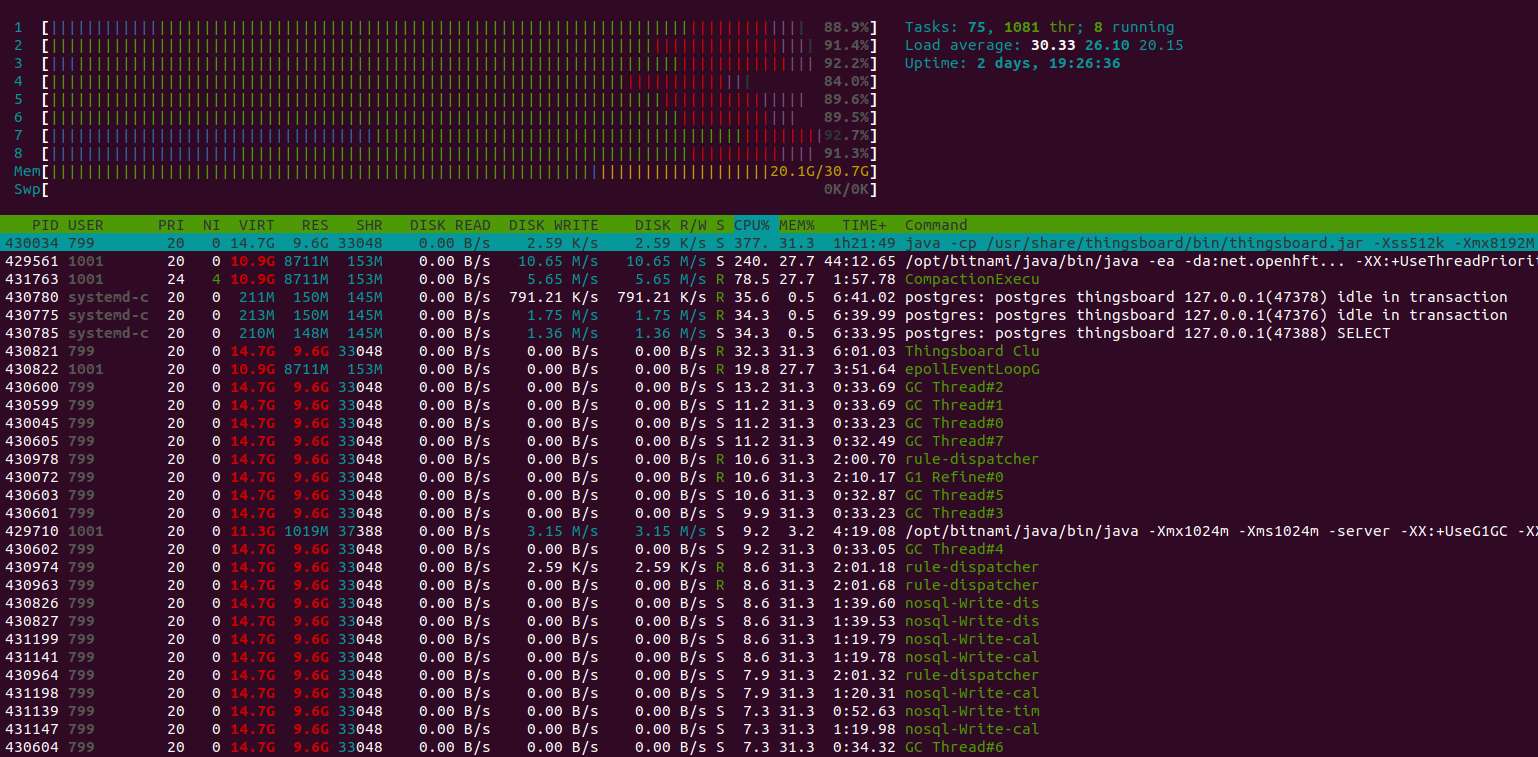
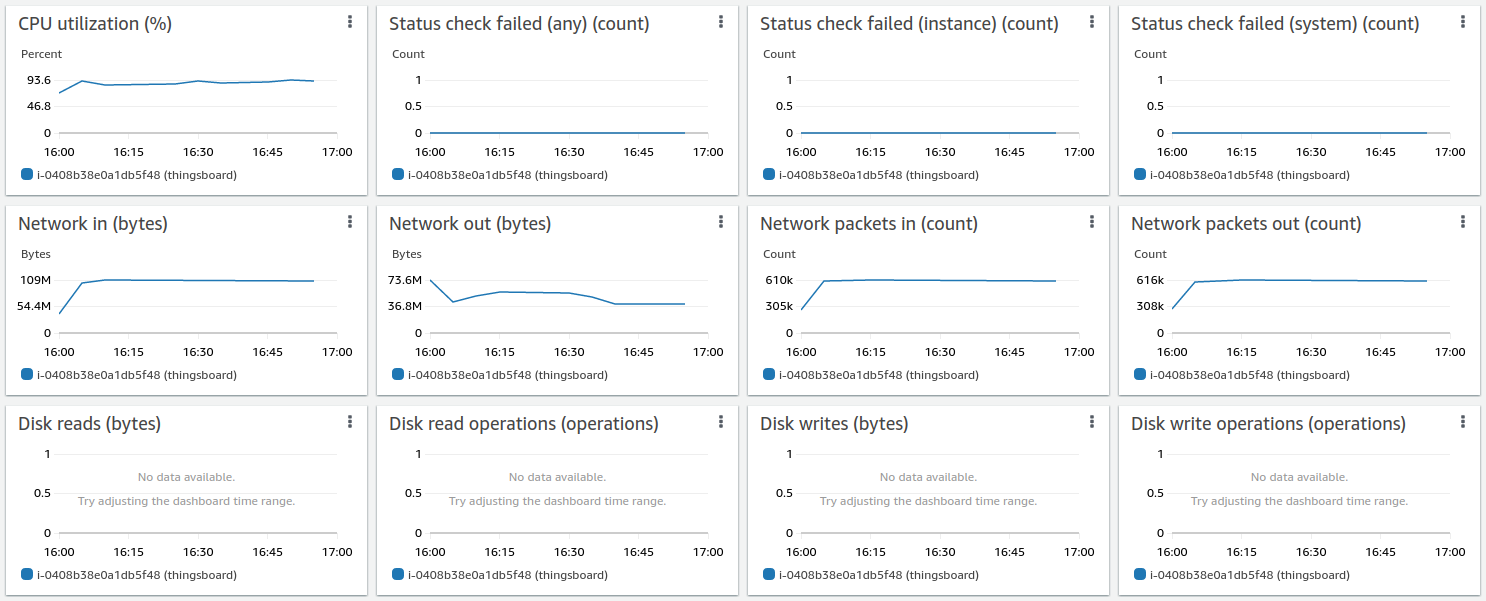
Here the 24h run results:
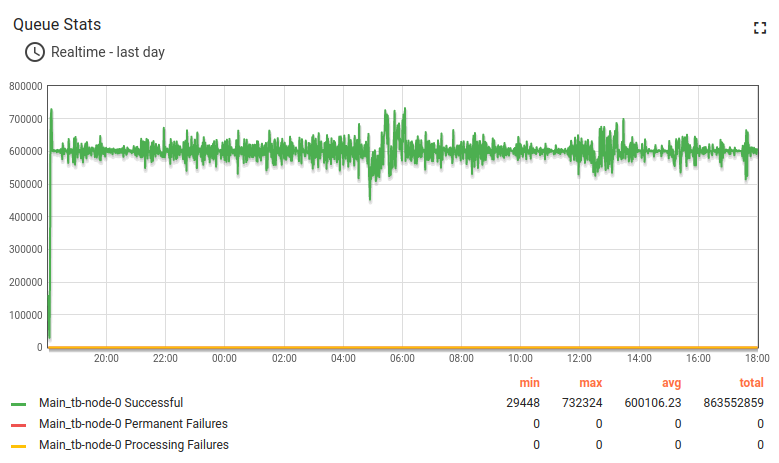
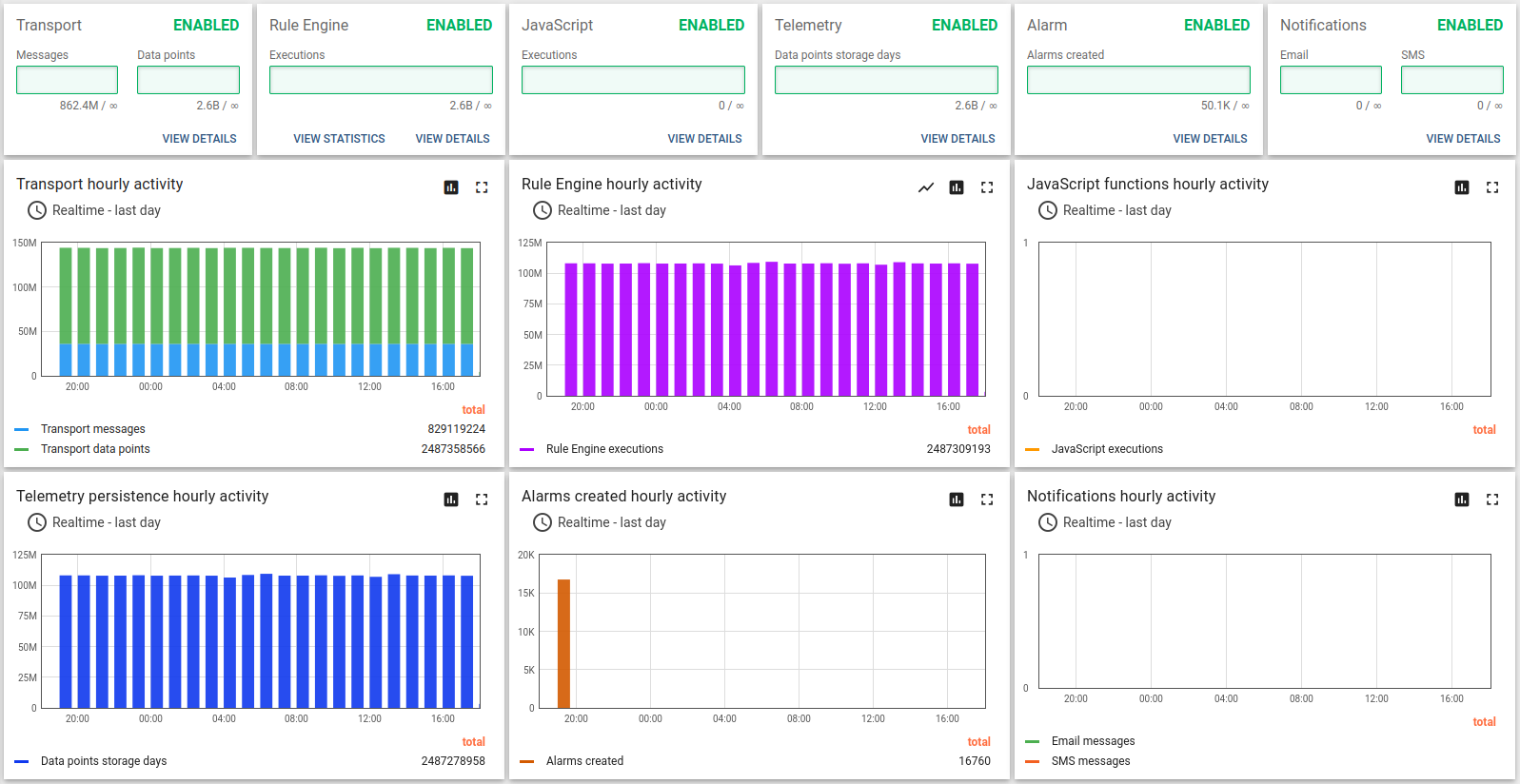
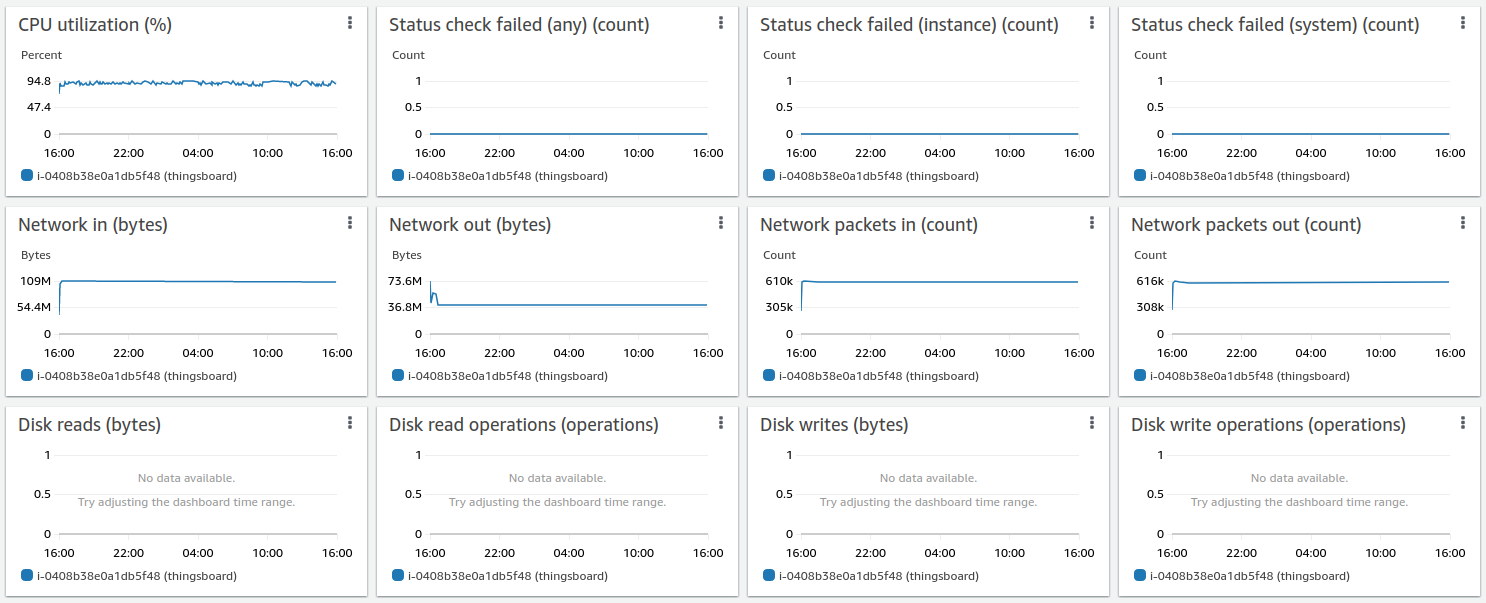
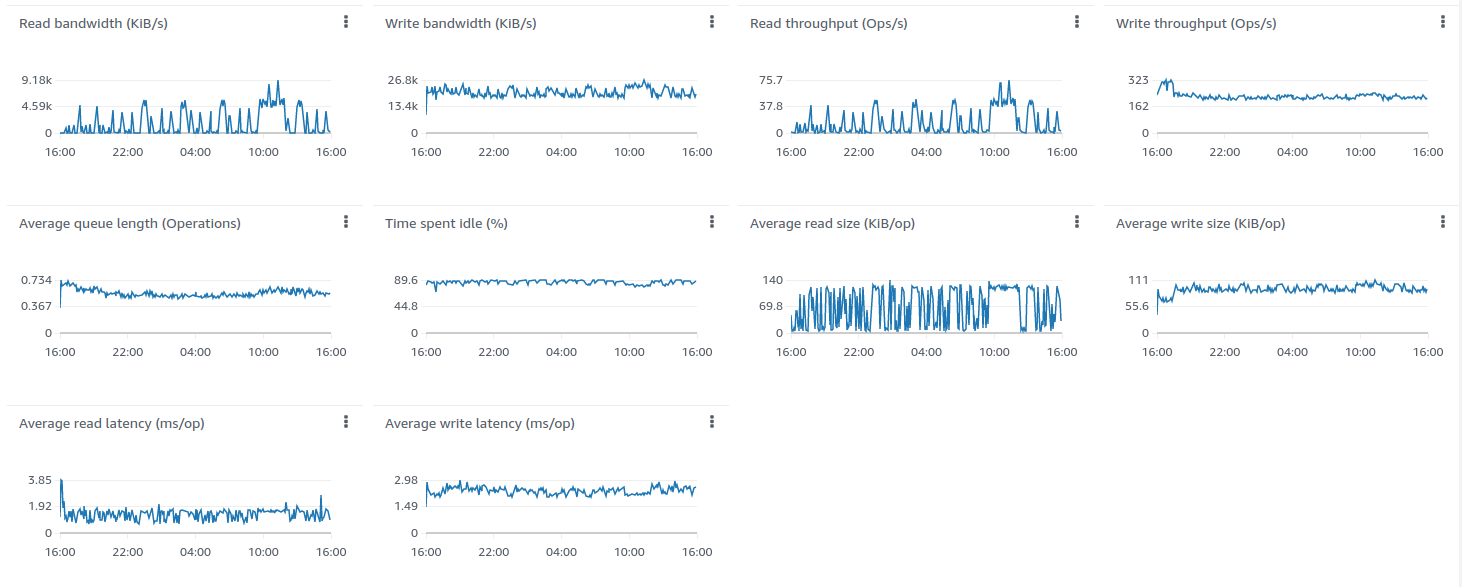
Lessons learned:
The m6a.2xlarge can handle up to 100k devices with a message rate of up to 10k/sec. CPU usage is 93%, so there are almost no extra resources left for a peak load and user activities.
How to reproduce the test:
Setup the ThingsBoard instance on AWS EC2
Use the Docker Compose file listed below to setup the AWS EC2 instance based on the instruction.
Here the docker-compose with ThingsBoard + Postgresql + Zookeeper + Kafka + Cassandra
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
version: '3.0'
services:
cassandra:
image: bitnamilegacy/cassandra:4.0
network_mode: "host"
restart: "always"
volumes:
- cassandra:/bitnami
environment:
CASSANDRA_CLUSTER_NAME: "ThingsBoard Cluster"
HEAP_NEWSIZE: "4096M"
MAX_HEAP_SIZE: "8192M"
JVM_EXTRA_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=7199 -Dcom.sun.management.jmxremote.rmi.port=7199 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
zookeeper:
image: bitnamilegacy/zookeeper:3.7
network_mode: "host"
restart: "always"
volumes:
- zookeeper:/bitnami
environment:
ALLOW_ANONYMOUS_LOGIN: "yes"
ZOO_ENABLE_ADMIN_SERVER: "no"
JVMFLAGS: "-Xmx128m -Xms128m -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9199 -Dcom.sun.management.jmxremote.rmi.port=9199 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
kafka:
image: bitnamilegacy/kafka:3
network_mode: "host"
restart: "always"
volumes:
- kafka:/bitnami
environment:
KAFKA_CFG_ZOOKEEPER_CONNECT: "localhost:2181"
ALLOW_PLAINTEXT_LISTENER: "yes"
KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.rmi.port=1099 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
JMX_PORT: "1099"
depends_on:
- zookeeper
postgres:
image: "postgres:14"
network_mode: "host"
restart: "always"
volumes:
- postgres:/var/lib/postgresql/data
environment:
POSTGRES_DB: "thingsboard"
POSTGRES_PASSWORD: "postgres"
tb:
depends_on:
- postgres
- kafka
- cassandra
image: "thingsboard/tb"
network_mode: "host"
restart: "always"
volumes:
- thingsboard-data:/data
- thingsboard-logs:/var/log/thingsboard
environment:
DATABASE_TS_TYPE: "cassandra"
DATABASE_TS_LATEST_TYPE: "sql"
#Cassandra
CASSANDRA_CLUSTER_NAME: "ThingsBoard Cluster"
CASSANDRA_LOCAL_DATACENTER: "datacenter1"
CASSANDRA_KEYSPACE_NAME: "thingsboard"
CASSANDRA_URL: "127.0.0.1:9042"
CASSANDRA_USE_CREDENTIALS: "true"
CASSANDRA_USERNAME: "cassandra"
CASSANDRA_PASSWORD: "cassandra"
CASSANDRA_QUERY_BUFFER_SIZE: "200000"
CASSANDRA_QUERY_CONCURRENT_LIMIT: "1000"
CASSANDRA_QUERY_POLL_MS: "5"
#Kafka
TB_QUEUE_TYPE: "kafka"
TB_KAFKA_BATCH_SIZE: "65536" # default is 16384 - it helps to produce messages much efficiently
TB_KAFKA_LINGER_MS: "5" # default is 1
TB_QUEUE_KAFKA_MAX_POLL_RECORDS: "2048" # default is 8192
TB_SERVICE_ID: "tb-node-0"
HTTP_BIND_PORT: "8080"
TB_QUEUE_RE_MAIN_PACK_PROCESSING_TIMEOUT_MS: "30000"
# Postgres connection
SPRING_DATASOURCE_URL: "jdbc:postgresql://localhost:5432/thingsboard"
SPRING_DATASOURCE_USERNAME: "postgres"
SPRING_DATASOURCE_PASSWORD: "postgres"
# Cache specs
CACHE_SPECS_DEVICES_MAX_SIZE: "512000" # default is 10000
CACHE_SPECS_DEVICE_CREDENTIALS_MAX_SIZE: "512000" # default is 10000
CACHE_SPECS_SESSIONS_MAX_SIZE: "512000" # default is 10000
TS_KV_PARTITIONS_MAX_CACHE_SIZE: "3000000" # default is 100000
# Device state service
DEFAULT_INACTIVITY_TIMEOUT: "1800" # defailt is 600 (10min)
DEFAULT_STATE_CHECK_INTERVAL: "600" # default is 60 (1min)
PERSIST_STATE_TO_TELEMETRY: "true" # Persist device state to the Cassandra. Default is false (Postgres, as device server_scope attributes)
# Java options for 16G instance and JMX enabled
JAVA_OPTS: " -Xmx8192M -Xms8192M -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9999 -Dcom.sun.management.jmxremote.rmi.port=9999 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1"
ulimits:
nofile:
soft: 1048576
hard: 1048576
volumes: # to persist data between container restarts or being recreated
cassandra:
kafka:
zookeeper:
postgres:
thingsboard-data:
thingsboard-logs:
Launch performance test tool on two nodes
Use the Docker command listed below to launch the performance test tool based on the instruction.
We need at least two performance-test instances to produce 100k simultaneous connections because each test instance may create up to 65535 simultaneous connections to a particular external server. By default, Ubuntu Linux allows you to spin up a 28232 outgoing connection providing a local port range from 32768 to 60999. So, we need to increase the IP local port range on a performance test instance that setup many outgoing connections. Now we can open up to 64511 IP ports.
1
2
3
4
5
6
7
8
9
10
ssh pt
cat /proc/sys/net/ipv4/ip_local_port_range
#32768 60999
echo "net.ipv4.ip_local_port_range = 1024 65535" | sudo tee -a /etc/sysctl.conf
sudo -s sysctl -p
cat /proc/sys/net/ipv4/ip_local_port_range
#1024 65535
ulimit -n 1048576
sudo sysctl -a | grep conntrack_max
sudo sysctl -w net.netfilter.nf_conntrack_max=1048576
Here is the run script for the first node.
1
2
3
4
5
6
7
8
9
10
11
12
# Put your ThingsBoard private IP address here, assuming both ThingsBoard and performance tests EC2 instances are in same VPC.
export TB_INTERNAL_IP=172.31.16.229
docker run -it --rm --network host --name tb-perf-test \
--env REST_URL=http://$TB_INTERNAL_IP:8080 \
--env MQTT_HOST=$TB_INTERNAL_IP \
--env DEVICE_START_IDX=0 \
--env DEVICE_END_IDX=50000 \
--env MESSAGES_PER_SECOND=2500 \
--env ALARMS_PER_SECOND=10 \
--env DURATION_IN_SECONDS=86400 \
--env DEVICE_CREATE_ON_START=true \
thingsboard/tb-ce-performance-test:3.3.3
Here is the run script for the second node. Note the DEVICE_START_IDX and DEVICE_END_IDX values are different from the one we used on the first node.
1
2
3
4
5
6
7
8
9
10
11
12
# Put your ThingsBoard private IP address here, assuming both ThingsBoard and performance tests EC2 instances are in same VPC.
export TB_INTERNAL_IP=172.31.16.229
docker run -it --rm --network host --name tb-perf-test \
--env REST_URL=http://$TB_INTERNAL_IP:8080 \
--env MQTT_HOST=$TB_INTERNAL_IP \
--env DEVICE_START_IDX=50000 \
--env DEVICE_END_IDX=100000 \
--env MESSAGES_PER_SECOND=2500 \
--env ALARMS_PER_SECOND=10 \
--env DURATION_IN_SECONDS=86400 \
--env DEVICE_CREATE_ON_START=true \
thingsboard/tb-ce-performance-test:3.3.3
Additional checks
Here are some pointers on how to ensure that you have a valid test run with all devices created and connected
-
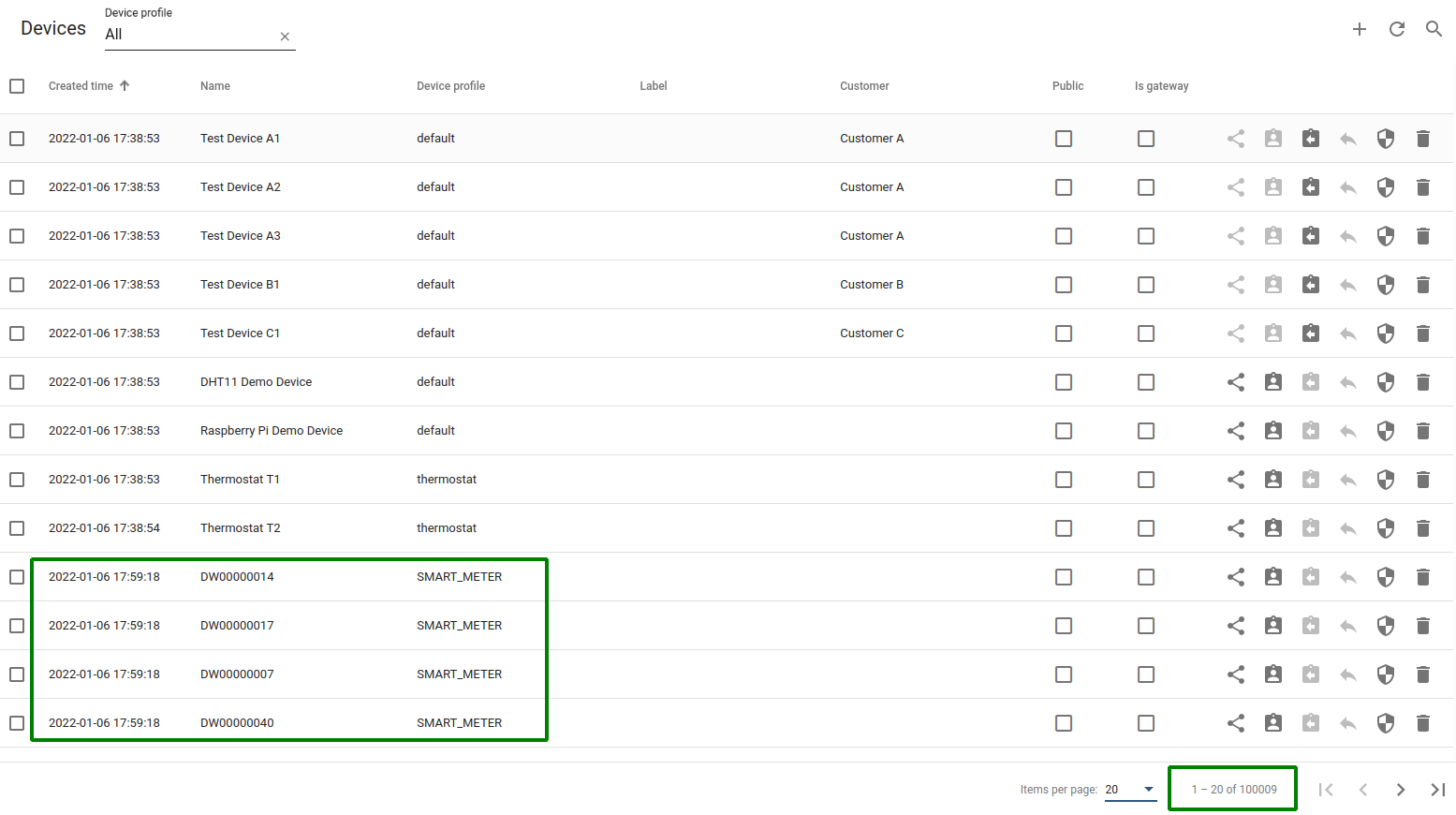
All devices created. Open device List and check total device count. Device count has to be greater than 100k
-
All devices connected. Check Transport Stats in the logs.
1
tb_1 | 2022-01-06 16:37:11,716 [TB-Scheduling-3] INFO o.t.s.c.t.s.DefaultTransportService - Transport Stats: openConnections [100000]
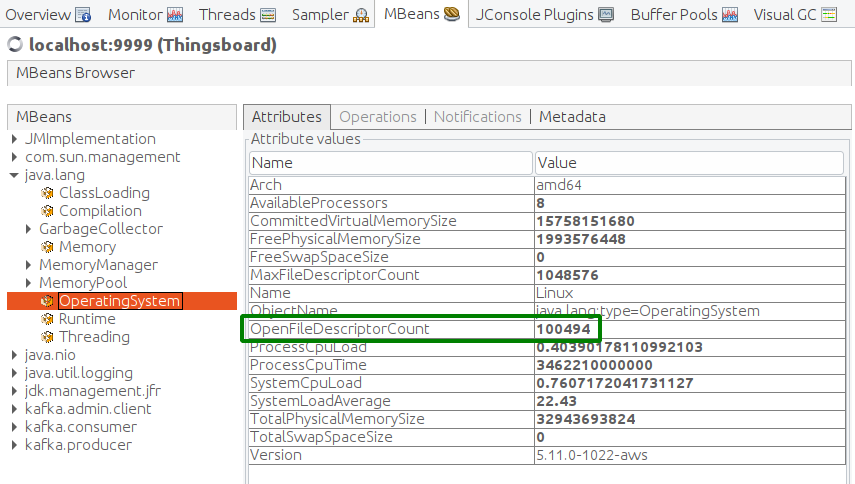
- All device connected. Java JMX. VisualVM -> ThingsBoard -> MBeans -> java.lang -> OpenFileDescriptorCount -> more than 100000
Disk usage
Postgres
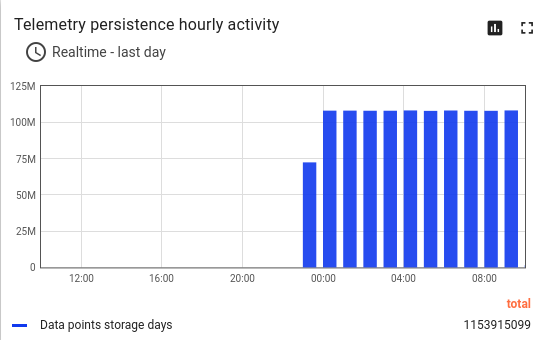
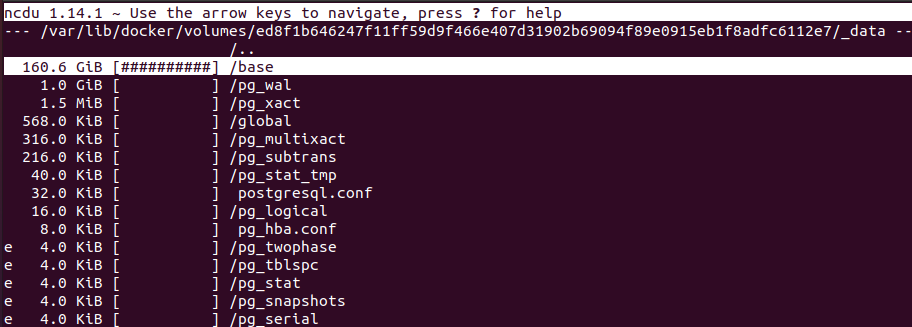
By the end of the day in Scenario B, the system run out of the disk space.
The 200Gb disk was filled out in about 24 hours with average 5k msg/sec, 15k datapoints/sec; total messages 363M, data points 1.1B.
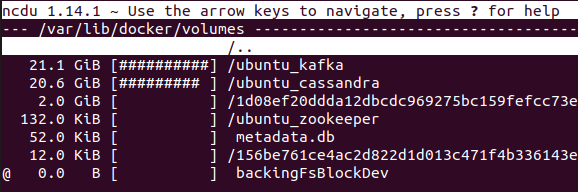
Postgres database size is 160GiB. It is about 7M data points per 1 GiB disk space. To reach much better disk space efficiency please, check the Cassandra disk space usage.
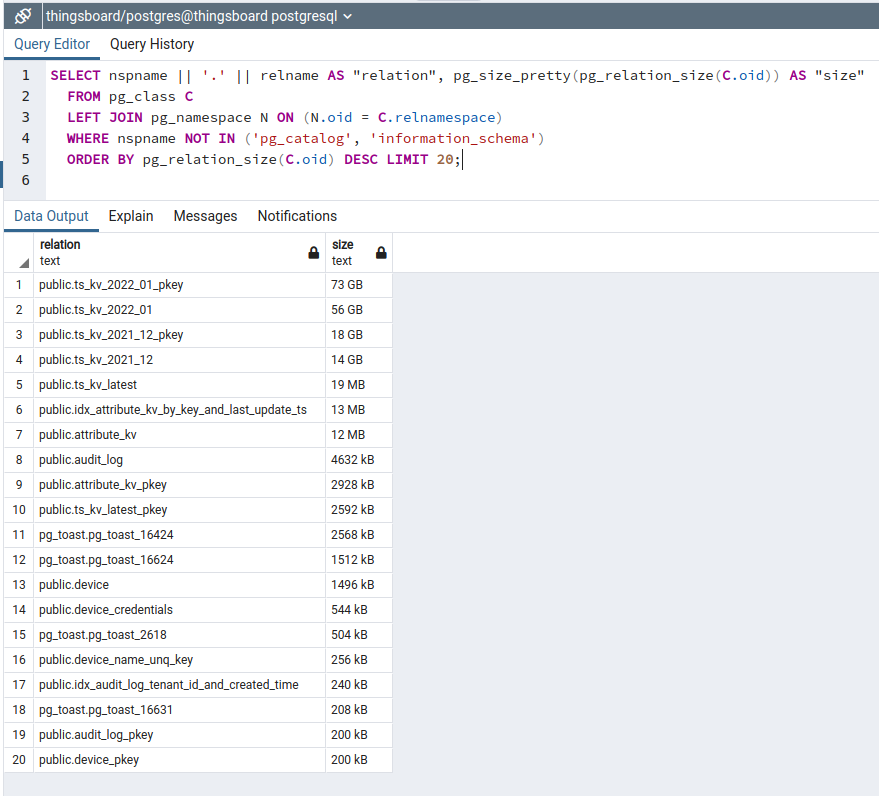
Detailed PostgreSQL disk usage by tables and indexes
1
2
3
4
5
SELECT nspname || '.' || relname AS "relation", pg_size_pretty(pg_relation_size(C.oid)) AS "size"
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
WHERE nspname NOT IN ('pg_catalog', 'information_schema')
ORDER BY pg_relation_size(C.oid) DESC LIMIT 20;
You can see the biggest table is timeseries (TS, telemetry, data points) and TS index. All telemetry divided my month to gain a stable performance.
Test started in December and finished in January. The TS have two tables 2021_12 and 2022_01 for respective months.
Kafka size is 20GiB.
Tip: to plan and manage the Kafka disk space, please, adjust the size retention policy and period retention policy.

Cassandra - disk usage
For 24 hours (100k devices, 432M msg) total datapoint stored is 1.3B
Cassandra’s disk usage is about 20 GiB per 1.3B data points. It is about 65M data points per 1 GiB disk space.
Note: data size on disk may vary depends on the content.
Disk usage summary
Compared with Postgresql, Cassandra’s disk space consumption is about x5-x10 times less.
Cassandra’s advantage is the data compression and less overhead in a data structure.
Another benefit is Cassandra does less write operations than Postgres. It is enough to order storage with a standard IOPS plan and save money.
Thank you
Thank you for taking your time to read all this stuff. Thanks to the ThingsBoard community that creates issues and shares performance solutions around the time. Thanks to Sergey for performing the tests, performance improvements, and contribution to this article.
It was ThingsBoard 3.3.3 version. We will work on performance improvements in 3.4.x
Feel free to send us feedback or share your fancy setup on GitHub