- Introduction
- Motivation
- How does TBMQ work in a nutshell?
- Standalone vs cluster mode
- Programming languages
Introduction
This article explains the architectural structure of TBMQ, breaking down how data moves between different components and outlining the core architectural choices. TBMQ is designed with great care to implement the following attributes:
- Scalability: it is a horizontally scalable platform constructed using cutting-edge open-source technologies;
- Fault tolerance: no single point of failure; each broker (node) within the cluster is identical in terms of functionality;
- Robustness and efficiency: can manage millions of clients and process millions of messages per second;
- Durability: provides high message durability, ensuring that data is never lost.
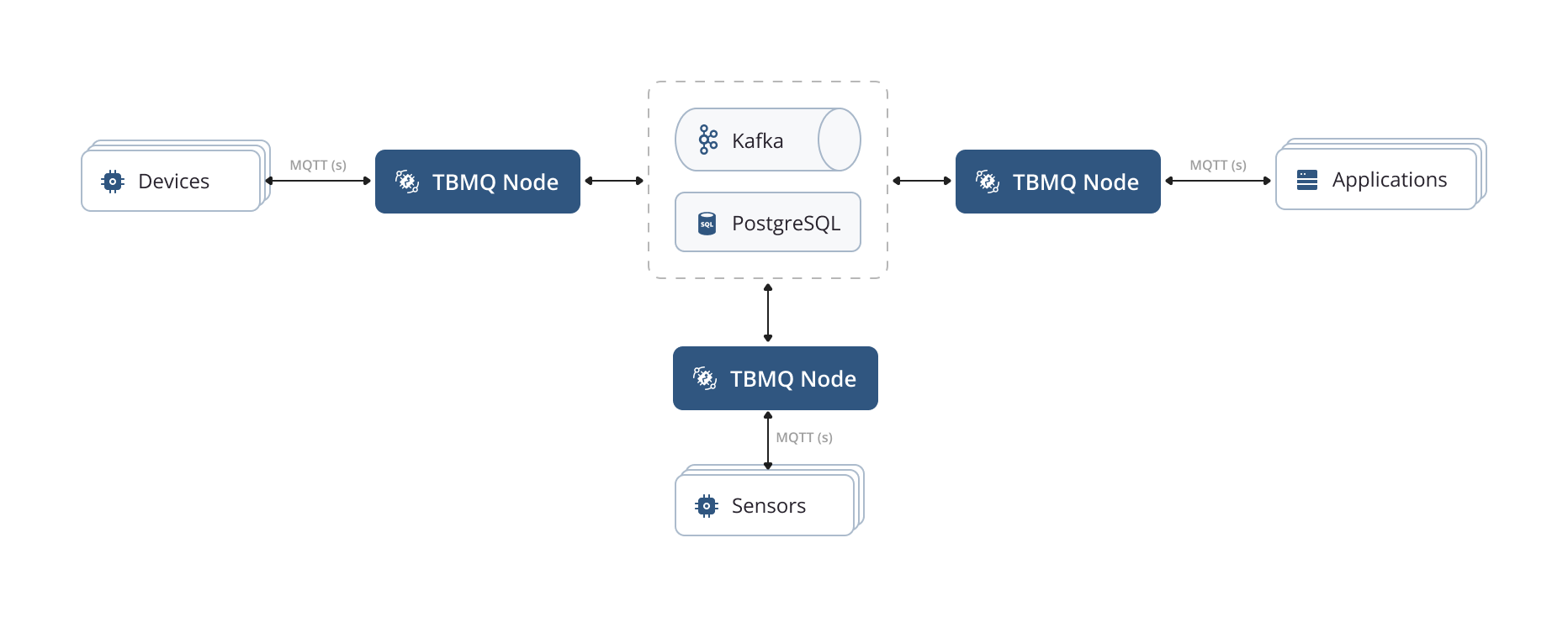
Architecture diagram
The following diagram shows the pivotal parts of the broker and the route of message transmission.
Motivation
At ThingsBoard, we’ve gained a lot of experience in building scalable IoT applications, which has helped us identify three main scenarios for MQTT-based solutions.
-
In the first scenario, numerous devices generate a large volume of messages that are consumed by specific applications, resulting in a fan-in pattern. Normally, a few applications are set up to handle these lots of incoming data. It must be ensured that they do not miss any single message.
-
The second scenario involves numerous devices subscribing to specific updates or notifications that must be delivered. This leads to a few incoming requests that cause a high volume of outgoing data. This case is known as a fan-out (broadcast) pattern.
-
The third scenario, point-to-point (P2P) communication, is a targeted messaging pattern, primarily used for one-to-one communication. Ideal for use cases such as private messaging or command-based interactions where messages are routed between a single publisher and a specific subscriber through uniquely defined topics.
In all scenarios, persistent clients with a Quality of Service (QoS) level set to 1 or 2 are often utilized to ensure reliable message delivery, even when they’re temporarily offline due to restarts or upgrades.
Acknowledging these scenarios, we intentionally designed TBMQ to be exceptionally well-suited for all three.
Our design principles focused on ensuring the broker’s fault tolerance and high availability. Thus, we deliberately avoided reliance on master or coordinated processes. We ensured the same functionality across all nodes within the cluster.
We prioritized supporting distributed processing, allowing for effortless horizontal scalability as our operations grow. We wanted our broker to support high-throughput and guarantee low-latency delivery of messages to clients. Ensuring data durability and replication was crucial in our design. We aimed for a system where once the broker acknowledges receiving a message, it remains safe and won’t be lost.
To ensure the fulfillment of the above requirements and prevent message loss in the case of clients or some of the broker instances failures, TBMQ uses the powerful capabilities of Kafka as its underlying infrastructure.
How does TBMQ work in a nutshell?
Kafka plays a crucial role in various stages of the MQTT message processing. All unprocessed published messages, client sessions, and subscriptions are stored within dedicated Kafka topics. A comprehensive list of Kafka topics used within TBMQ is available here. All broker nodes can readily access the most up-to-date state of client sessions and subscriptions by utilizing these topics. They maintain local copies of sessions and subscriptions for efficient message processing and delivery. When a client loses connection to a specific broker node, other nodes can seamlessly continue operations based on the latest state. Additionally, newly added broker nodes to the cluster get this vital information upon their activation.
Client subscriptions hold significant importance within the MQTT publish/subscribe pattern. TBMQ employs the Trie data structure to optimize performance, enabling efficient persistence of client subscriptions in memory and facilitating swift access to relevant topic patterns.
Upon a publisher client sending a PUBLISH message, it is stored in the initial Kafka topic, tbmq.msg.all. Once Kafka acknowledges the message’s persistence, the broker promptly responds to the publisher with either a PUBACK/PUBREC message or no response at all, depending on the chosen QoS level.
Subsequently, separate threads, functioning as Kafka consumers, retrieve messages from the mentioned Kafka topic and utilize the Subscription Trie data structure to identify the intended recipients. Depending on the client type (DEVICE or APPLICATION) and the persistence options described below, the broker either redirects the message to another specific Kafka topic or directly delivers it to the recipient.
Non-persistent client
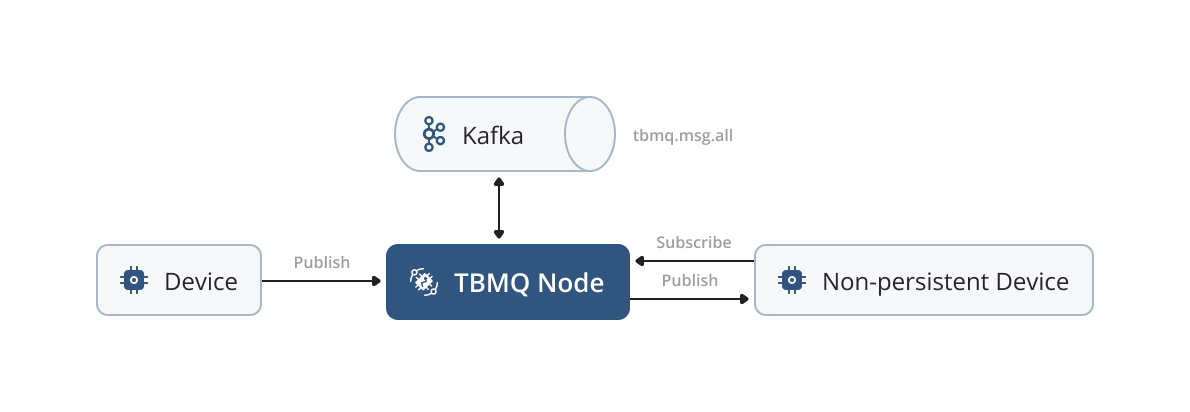
A client is classified as a non-persistent one when the following conditions are met in the CONNECT packet:
For MQTT v3.x:
clean_sessionflag is set to true.
For MQTT v5:
clean_startflag is set to true andsessionExpiryIntervalis set to 0 or not specified.
In the case of non-persistent clients, all messages intended for them are published directly without undergoing additional persistence. It is important to note that non-persistent clients can only be of type DEVICE.
Non-persistent DEVICE processing in cluster mode
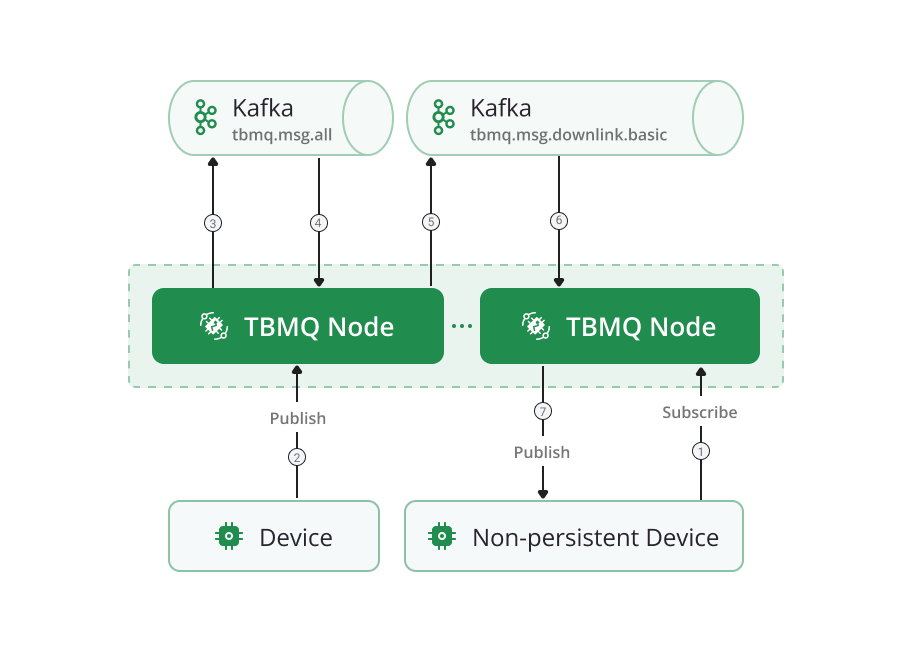
In cluster mode, multiple TBMQ nodes can operate together, each running Kafka consumers in the same consumer group for the tbmq.msg.all topic. This approach ensures efficient load balancing and message distribution across nodes. However, it can result in scenarios where a published message is processed by one TBMQ node while the intended subscriber is connected to another. To handle this, downlink.basic Kafka topic is used for communication between TBMQ nodes. This ensures that the node processing the message forwards it to the target node, which then delivers it to the subscriber via the established connection.
Persistent client
MQTT clients that do not meet the non-persistent conditions mentioned above are categorized as persistent clients. Let’s delve into the conditions for persistent clients:
For MQTT v3.x:
clean_sessionflag is set to false.
For MQTT v5 clients:
sessionExpiryIntervalis greater than 0 (regardless of theclean_startflag).clean_startflag is set to false andsessionExpiryIntervalis set to 0 or not specified.
Building on our knowledge within the IoT ecosystem and the successful implementation of numerous IoT use cases, we have classified MQTT clients into two distinct categories:
-
The DEVICE clients primarily engaged in publishing a significant volume of messages while subscribing to a limited number of topics with relatively low message rates. These clients are typically associated with IoT devices or sensors.
-
The APPLICATION clients specialize in subscribing to topics with high message rates. They often require messages to be persisted when the client is offline with later delivery, ensuring the availability of crucial data. These clients are commonly used for real-time analytics, data processing, or other application-level functionalities.
Consequently, we made a strategic decision to optimize performance by separating the processing flow for these two types of clients.
Persistent DEVICE client
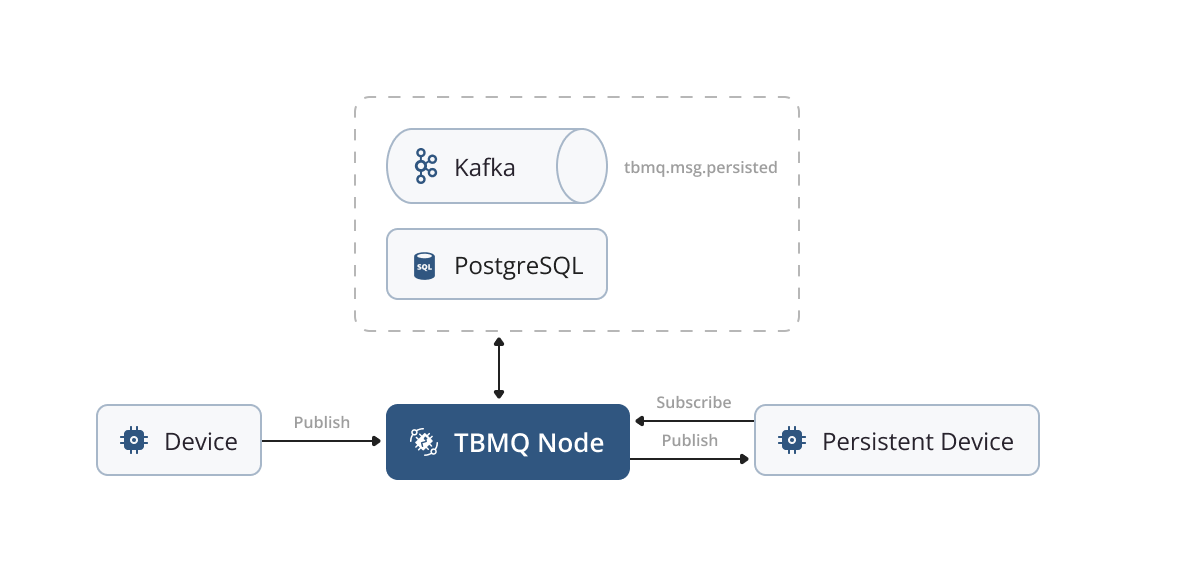
For DEVICE persistent clients, we use the tbmq.msg.persisted Kafka topic as a means of processing published messages that are extracted from the tbmq.msg.all topic. This design separates the handling of persistent messages from other message types, ensuring a clear and efficient workflow. Dedicated threads, functioning as Kafka consumers, retrieve these messages and store them in a Redis database utilized for persistence storage. This method is particularly suitable for DEVICE clients, as they typically do not require extensive message reception. This approach helps us recover stored messages smoothly when a client reconnects. At the same time, it ensures great performance for scenarios involving a moderate incoming message rate.
A detailed breakdown of how we use Redis as persistent message storage for DEVICE clients is available here.
Persistent DEVICE processing in cluster mode
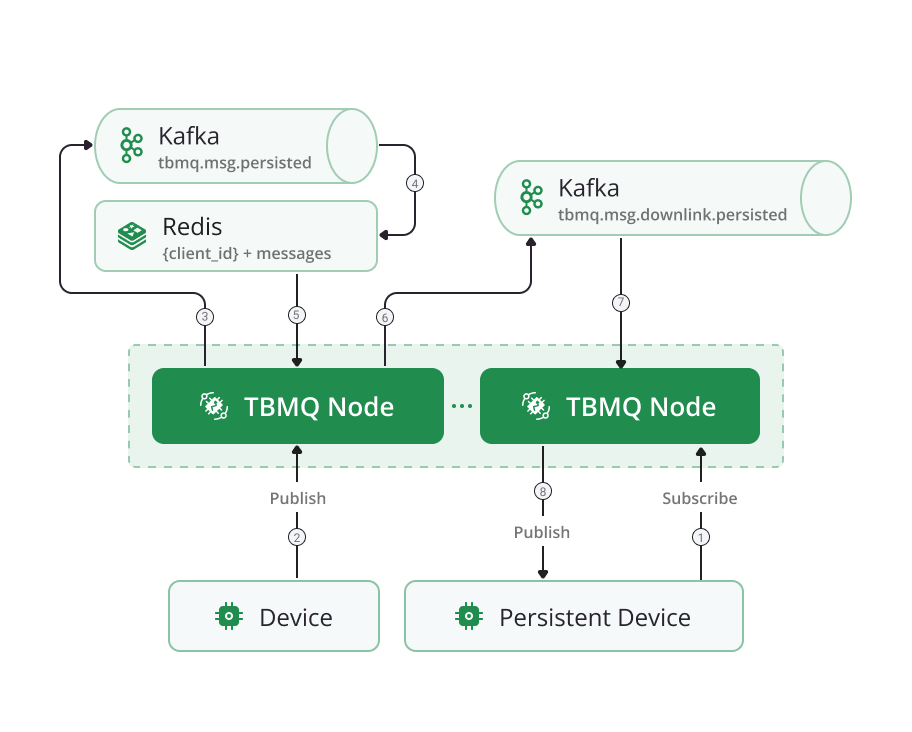
Similarly to non-persistent clients, TBMQ nodes in cluster mode operate together, running Kafka consumers in the same group for the tbmq.msg.persisted topic. To handle cases where a message is processed by one node but the subscriber is connected to another, downlink.persisted Kafka topic is used to forward the message to the appropriate node. This ensures seamless delivery to the subscriber via its established connection.
Persistent APPLICATION client
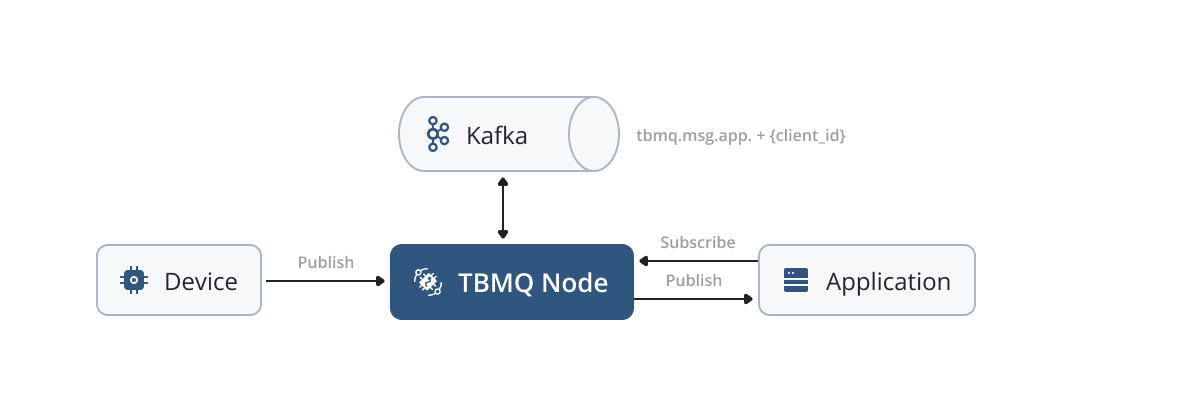
The number of APPLICATION clients corresponds to the number of Kafka topics used. The latest version of Kafka can handle millions of topics, making this design suitable even for the largest enterprise use cases.
Any message read from the tbmq.msg.all topic meant for a specific APPLICATION client is then stored in the corresponding Kafka topic. A separate thread (Kafka consumer) is assigned to each APPLICATION. These threads retrieve messages from the corresponding Kafka topics and deliver them to the respective clients. This approach significantly improves performance by ensuring efficient message delivery. Additionally, the nature of the Kafka consumer group makes the MQTT 5 shared subscription feature extremely efficient for APPLICATION clients.
APPLICATION clients can handle a large volume of received messages, reaching millions per second. It is important to note that APPLICATION clients can only be classified as persistent.
For both types of clients, we provide configurable instruments to control the persistence of messages per client and the duration for which they are stored. You can refer to the following environment variables to adjust these settings:
- TB_KAFKA_APP_PERSISTED_MSG_TOPIC_PROPERTIES;
- MQTT_PERSISTENT_SESSION_DEVICE_PERSISTED_MESSAGES_LIMIT;
- MQTT_PERSISTENT_SESSION_DEVICE_PERSISTED_MESSAGES_TTL.
For more detailed information, please refer to the configurations provided in the following documentation.
Persistent APPLICATION processing in cluster mode
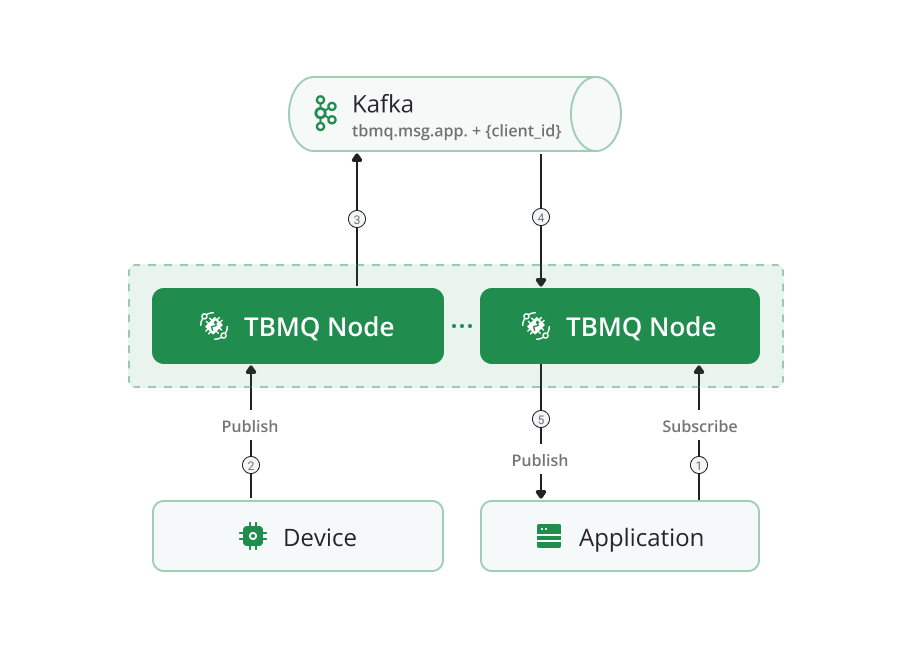
APPLICATION clients function the same way in cluster mode as in standalone setup, eliminating the need for internode communication. The processing of the message occurs directly on the target node, as a dedicated consumer for the APPLICATION client is created there once the client connects. This design ensures seamless and rapid message delivery. By avoiding additional message transmission steps, this approach ensures significantly improved performance, even as the system scales horizontally.
Kafka topics
Below is a comprehensive list of Kafka topics used within TBMQ, along with their respective descriptions.
- tbmq.msg.all - topic to store all published messages to the broker from MQTT clients.
- tbmq.msg.app. + ${client_id} - topic to store messages the APPLICATION client should receive based on its subscriptions.
- tbmq.msg.app.shared. + ${topic_filter} - topic to store messages the APPLICATION clients should receive based on their common shared subscription.
- tbmq.msg.persisted - topic to store messages the DEVICE persistent clients should receive based on their subscriptions.
- tbmq.msg.retained - topic to store all retained messages. Related to MQTT Retain messages feature.
- tbmq.client.session - topic to store sessions of all clients.
- tbmq.client.subscriptions - topic to store subscriptions of all clients.
- tbmq.client.session.event.request - topic to store events like CONNECTION_REQUEST, DISCONNECTION_REQUEST, CLEAR_SESSION_REQUEST, etc. for sessions of all clients.
- tbmq.client.session.event.response. + ${service_id} - topic to store responses to events of the previous topic sent to specific broker node where target client is connected.
- tbmq.client.disconnect. + ${service_id} - topic to store force client disconnection events (by admin request from UI/API or on sessions conflicts).
- tbmq.msg.downlink.basic. + ${service_id} - topic used to send messages from one broker node to another to which the DEVICE subscriber is currently connected.
- tbmq.msg.downlink.persisted. + ${service_id} - topic used to send messages from one broker node to another to which the DEVICE persistent subscriber is currently connected.
- tbmq.sys.app.removed - topic for events to process removal of APPLICATION client topic. Used when the client changes its type from APPLICATION to DEVICE.
- tbmq.sys.historical.data - topic for historical data statistics (e.g., number of incoming messages, outgoing messages, etc.) published from each broker node in the cluster to calculate the total values per cluster.
- tbmq.client.blocked - topic used to distribute and store the list of blocked clients, preventing them from establishing connections to the broker.
- tbmq.sys.internode.notifications + ${service_id} - topic for system-level notifications sent between broker nodes to synchronize authentication provider settings, authentication admin settings, and to trigger local client session cache cleanup.
Redis
Redis is a powerful, in-memory data store that excels in scenarios requiring low-latency and high-throughput data access, making it an ideal choice for storing real-time data.
In TBMQ, we utilize Redis to store messages for DEVICE persistent clients, allowing us to achieve high performance when handling the message persistence and delivery for these clients. Redis’s ability to manage large datasets in memory with lightning-fast read and write operations, combined with the scalability of Redis Cluster, ensures that persistent messages can be retrieved and delivered efficiently, even as the volume of stored messages grows and system demands increase. This scalability allows Redis to seamlessly handle larger workloads by distributing data across multiple nodes, maintaining high performance and reliability.
Before TBMQ v2.0, PostgreSQL was used for saving messages for DEVICE persistent clients. We migrated to Redis in v2.0 to provide a more scalable and performant solution for message persistence due to PostgreSQL limitations in terms of handling a high volume of write operations. This migration to Redis enables us to handle much higher throughput while ensuring fast, reliable message storage and delivery for DEVICE persistent clients.
PostgreSQL database
TBMQ uses a PostgreSQL database to store different entities such as users, user credentials, MQTT client credentials, statistics, WebSocket connections, WebSocket subscriptions, and others.
PostgreSQL, known for its reliability, robustness, and flexibility, is a powerful open-source relational database management system that ensures data integrity while supporting high transaction throughput. In TBMQ, PostgreSQL serves as the primary storage layer for persisting critical metadata about the system. Given the nature of MQTT applications, which involve high message volumes and frequent read/write operations, PostgreSQL’s transaction management and ACID compliance provide strong consistency guarantees, ensuring that important data is safely stored and retrievable in any scenarios.
Web UI
TBMQ offers a user-friendly and lightweight graphical user interface (GUI) that simplifies the administration of the broker in an intuitive and efficient manner. This GUI provides several key features to facilitate broker management:
- MQTT Client Credential Management: users can easily manage MQTT client credentials through the GUI, allowing for the creation, modification, and deletion of client credentials as needed.
- Client Session and Subscriptions Control: the GUI enables administrators to monitor and control the state of client sessions, including terminating, and managing active client connections. It also provides functionality to manage client subscriptions, allowing for the addition, removal, and modification of subscriptions.
- Shared Subscription Management: the GUI includes tools for managing shared subscriptions. Administrators can create and manage Application shared subscription entities, facilitating efficient message distribution to multiple subscribed clients of type APPLICATION.
- Retained Message Management: the GUI allows administrators to manage retained messages, which are messages that are saved by the broker and delivered to new subscribers.
- WebSocket Client: The GUI provides support for WebSocket client, allowing administrators to establish, monitor, and manage WebSocket connections. This feature allows users to interact with TBMQ via MQTT over WebSocket, enabling them to efficiently debug and test their connections and message flows in real-time.
In addition to these administrative features, the GUI provides monitoring dashboards that offer comprehensive statistics and insights into the broker’s performance. These dashboards provide key metrics and visualizations to facilitate real-time monitoring of essential broker statistics, enabling administrators to gain a better understanding of the system’s health and performance.
The combination of these features makes the GUI an invaluable tool for managing, configuring, and monitoring TBMQ in a user-friendly and efficient manner.
Netty
In our pursuit of leveraging cutting-edge technologies, we selected Netty for implementing the TCP server that facilitates the MQTT protocol, owing to its proven performance and flexibility.
Netty is a high-performance, asynchronous event-driven network framework well-suited for building scalable and robust network applications, making it an excellent fit for handling MQTT traffic in TBMQ. One of the primary reasons for choosing Netty is its efficient handling of large numbers of simultaneous connections. In IoT environments, where thousands or even millions of devices are constantly connected and exchanging data, Netty’s ability to handle concurrent connections with low resource consumption is invaluable.
Netty uses non-blocking I/O (NIO), allowing it to efficiently manage resources without needing a dedicated thread for each connection, greatly reducing overhead. This approach ensures high throughput and low-latency communication, even under heavy loads, making it ideal for the high demands of an MQTT broker like TBMQ.
Netty is highly flexible, allowing developers to customize the networking stack to meet specific protocol requirements. With its modular design, Netty provides the building blocks to easily implement protocol handling, message parsing, and connection management, while offering TLS encryption options, making it secure and extensible for future needs.
Actor system
TBMQ utilizes an Actor System as the underlying mechanism for implementing actors responsible for handling MQTT clients. The adoption of the Actor model enables efficient and concurrent processing of messages received from clients, thereby ensuring high-performance operation.
The broker uses its own custom implementation of an Actor System, specifically designed to meet the requirements of TBMQ. Within this system, two distinct types of actors are present:
- Client Actors: for every connected MQTT client, a corresponding Client actor is created. These actors are responsible for processing the main message types, such as CONNECT, SUBSCRIBE, UNSUBSCRIBE, PUBLISH, and others. The Client actors handle the interactions with the MQTT clients and help the execution of the associated message operations.
- Persisted Device Actors: in addition to the Client actors, an extra Persisted Device actor is created for all DEVICE clients that are categorized as persistent. These actors are specifically designated to manage the persistence-related operations and handle the storage and retrieval of messages for persistent DEVICE clients.
With the Actor System and various actor types, TBMQ efficiently processes messages concurrently, ensuring optimal performance and quick responses when dealing with client interactions.
For further insights into the Actor model, you can refer to the provided link.
Message dispatcher service
The Message dispatcher service is another core component of TBMQ’s architecture, responsible for managing the flow of messages between publisher clients and Kafka, ensuring safe processing, persistence, and efficient delivery to the appropriate subscribers.
The primary role of the Message dispatcher service begins once the message from the publisher is received via the Actor system. The service takes this message and publishes it to Kafka, ensuring that it is durably stored for safe processing and persistence. This step guarantees that messages are not lost, even in the event of node failures or temporary disconnections, making Kafka a reliable backbone for handling high volumes of MQTT traffic.
Once Kafka confirms the message is stored, the Message dispatcher service retrieves the message and leverages the Subscription Trie to analyze which subscribers are eligible to receive it. After identifying the appropriate subscribers, the Message dispatcher service determines how to handle the message based on the type of subscriber:
- DEVICE Non-Persistent Client: The message can be immediately delivered to the client.
- DEVICE Persistent Client: The message is published to DEVICE clients Kafka topic and later stored in Redis.
- APPLICATION Persistent Client: The message is published to dedicated Application Kafka topic.
Once the appropriate handling route is determined and done for each subscriber, the message is passed to Netty, which manages the actual network transmission, ensuring the message is delivered to the appropriate online clients.
Subscriptions Trie
The Trie data structure is highly efficient for fast lookups due to its hierarchical organization and prefix-based matching. It allows for quick identification of matching topics by storing common prefixes only once, which minimizes search space and reduces memory usage. Its predictable time complexity, which depends on the length of the topic rather than the number of topics, ensures consistent and fast lookups even in large-scale environments with millions of subscriptions.
Within TBMQ, all client subscriptions are consumed from a Kafka topic and stored in a Trie data structure in the memory. The Trie organizes the topic filters hierarchically, with each node representing a level in the topic filter.
When a PUBLISH message is read from Kafka, the broker needs to identify all clients with relevant subscriptions for the topic name of the published message to ensure they receive the message. The Trie data structure enables efficient retrieval of client subscriptions based on the topic name. Once the relevant subscriptions are identified, a copy of the message is forwarded to each respective client.
This approach ensures high-performance message processing as it allows for quick and precise determination of the clients that need to receive a specific message. However, it is worth noting that this method requires increased memory consumption by the broker due to the storage of the Trie data structure.
For more detailed information on the Trie data structure, you can refer to the provided link.
Standalone vs cluster mode
TBMQ is designed to be horizontally scalable, allowing for the addition of new broker nodes to the cluster automatically. All nodes within the cluster are identical and share the overall load, ensuring a balanced distribution of client connections and message processing.
The design of the broker eliminates the need for “master” or “coordinator” processes, as there is no hierarchy or central node responsible for managing the others. This decentralized approach removes the presence of a single point of failure, enhancing the system’s overall robustness and fault tolerance.
To handle client connection requests, a load balancer of your choice can be used. The load balancer distributes incoming client connections across all available TBMQ nodes, evenly distributing the workload and maximizing resource utilization.
In the event that a client loses its connection with a specific broker node (e.g., due to node shutdown, removal, or network failure), it can easily reconnect to any other healthy node within the cluster. This seamless reconnection capability ensures continuous operation and uninterrupted service for connected clients, as they can establish connections with any available node in the cluster.
By leveraging horizontal scalability, load balancing, and automatic discovery of new nodes, TBMQ provides a highly scalable and resilient architecture for handling MQTT communication in large-scale deployments.
Programming languages
The back end of TBMQ is implemented in Java 17. The front end of TBMQ is developed as a SPA using the Angular 19 framework.