In the early stages of an IoT project, storage is an afterthought. But as you scale from pilot to production, telemetry volume doesn’t just grow—it intensifies. At ThingsBoard, we have monitored this trend across a vast number of diverse production environments: the very data that provides your competitive edge can quickly become your largest infrastructure cost driver.
While high-frequency, “per-second” telemetry is non-negotiable for real-time monitoring and granular troubleshooting, keeping every raw data point for years is rarely a sustainable business strategy.
Based on the patterns we’ve observed in high-scale deployments, we have developed a “Production Receipt” for data efficiency. This guide outlines how to master the Telemetry Lifecycle by combining intelligent aggregation with explicit data retention rules.
By implementing this recipe, you can slash long-term storage overhead and TCO (Total Cost of Ownership) while ensuring your historical dashboards remain efficient, meaningful, and accurate.
The Reality of Linear Scaling
While a “store-everything” approach is manageable for a small pilot, storage requirements scale linearly with your fleet size. In a production environment, this volume quickly transforms from a technical metric into a financial liability.
To visualize the scaling, consider the footprint of just one telemetry key reporting once per minute (assuming 32 bytes per record and a standard replication factor of 3):
10 Devices (Pilot Scale)
At a small scale, the cumulative data impact is negligible:
- Data points per day: ~14,400
- Data points per year: ~5.25 million
- Total stored volume (inc. replication): ~500 MB per year
Verdict: At this scale, storage strategy is rarely a priority.
50,000 Devices (Production Scale)
Applying that same retention logic to an enterprise fleet results in massive infrastructure overhead:
- Data points per day: ~72 million
- Data points per year: ~26.2 billion
- Total stored volume (inc. replication): ~2.5 TB per year
- Over 5 Years: ~12.5 TB of raw telemetry
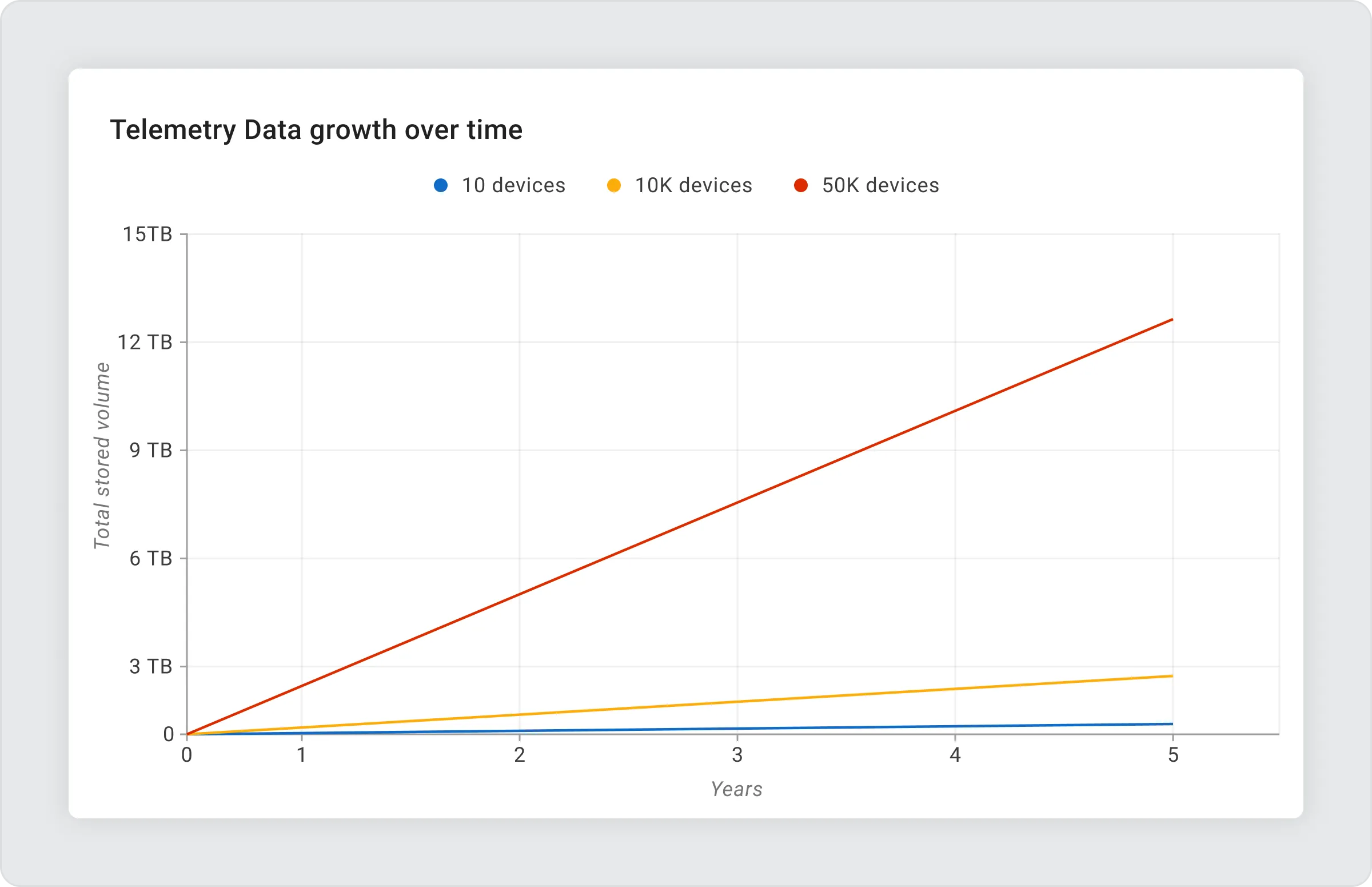
Without a defined lifecycle strategy, you effectively pay premium infrastructure rates to store over 12 Terabytes of data—much of which may have lost its operational utility minutes after it was generated.
How Telemetry Is Actually Used
In practice, telemetry data serves two very different purposes. Understanding this distinction is key to designing an efficient storage strategy.

Because analytical telemetry focuses on trends rather than exact values, aggregation becomes a practical and effective method for summarizing data over time. This reduces unnecessary detail while preserving the insights needed for long-term analysis.
Impact of Aggregation on Data Volume
Aggregation dramatically reduces the number of stored data points. The following table shows the reduction in data points for 10,000 devices over a 5-year period:
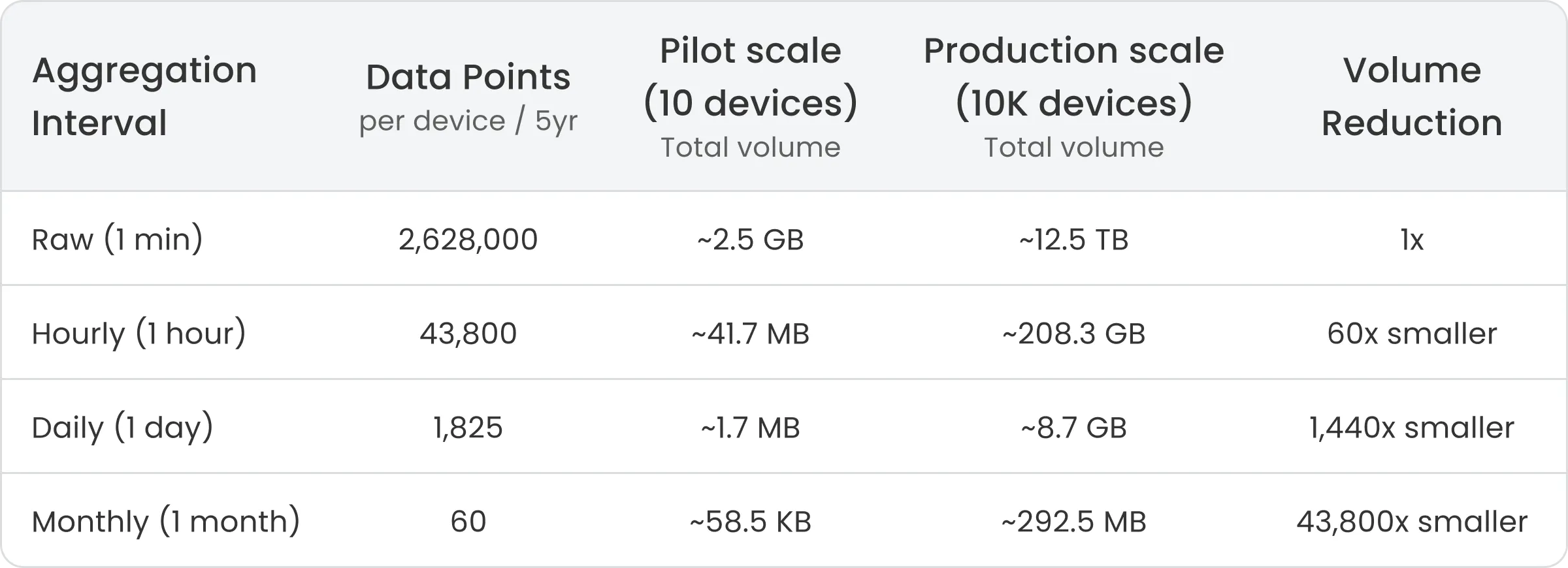
Larger aggregation intervals drastically reduce long-term storage requirements, while smaller intervals preserve more analytical detail. The optimal choice depends on how much historical precision is required for trend analysis and reporting.
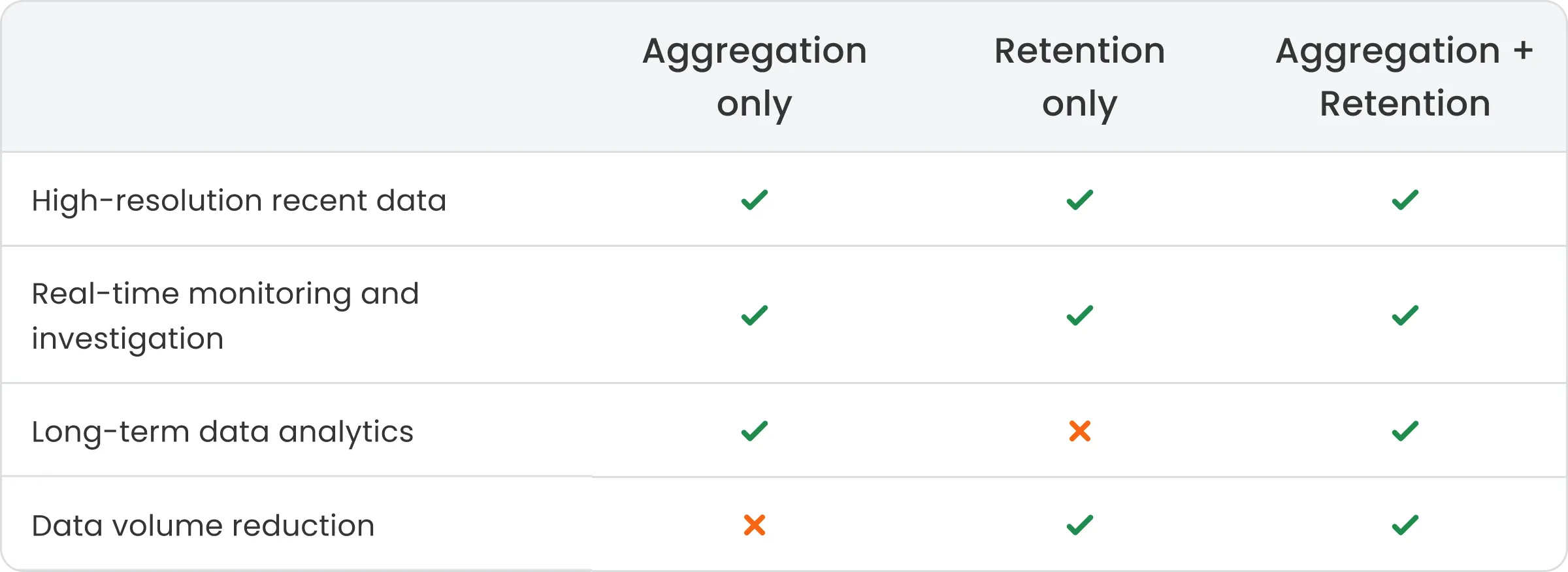
The Solution: Aggregation + Retention
Combining aggregation with explicit data retention rules defines a complete telemetry data lifecycle. Aggregation and retention address different aspects of telemetry storage and are most effective when used together.
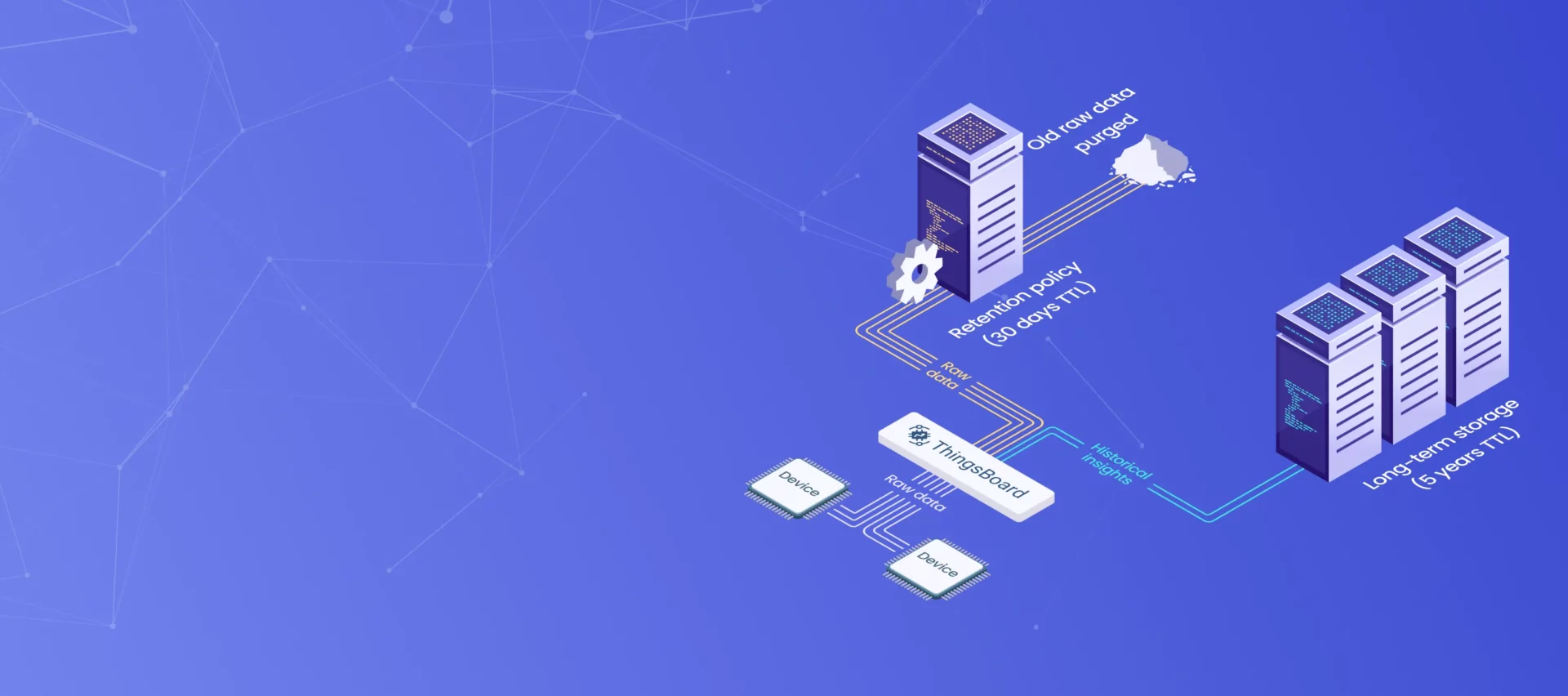
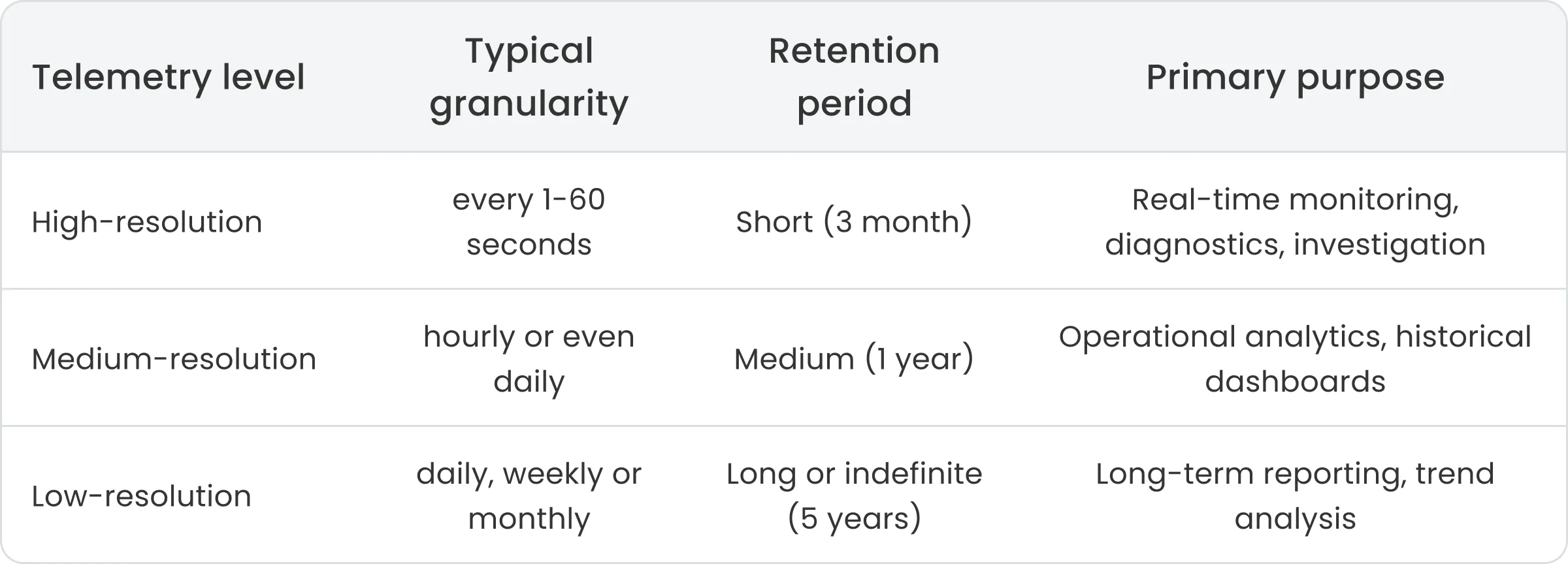
Multi-Level Retention Strategy
To efficiently manage telemetry data over time, it’s common to define multiple aggregation levels, where higher-level aggregations are based on already aggregated data. This allows you to retain different levels of data for different durations:
Here’s the impact on database storage for a single telemetry key recorded once per minute over five years:
- Raw Telemetry: 1-minute telemetry for 5 years ~2,628,000 data points.
- The Multi-Level Strategy:
- High-Res (3 Months): 129,600 points.
- Medium-Res (1 Year): 8,760 points.
- Low-Res (5 Years): 1,825 points.
- Total Stored: 140,185 points.
Storage savings: ~94.7% compared to keeping all raw data.
Implementing Aggregation and Retention in ThingsBoard
The implementation consists of two independent but complementary steps:
Step 1. Define aggregation logic using calculated fields
Aggregation is implemented using a Time Series Data Aggregation calculated field.
They summarize telemetry over fixed time intervals and write the results as new telemetry keys.
Each calculated field can have its own TTL, independent of the raw data. This allows aggregated data to be retained for a specific period that matches its analytical purpose, even after raw telemetry has been deleted. By explicitly setting TTL for each calculated field, you control exactly how long each aggregation is stored.
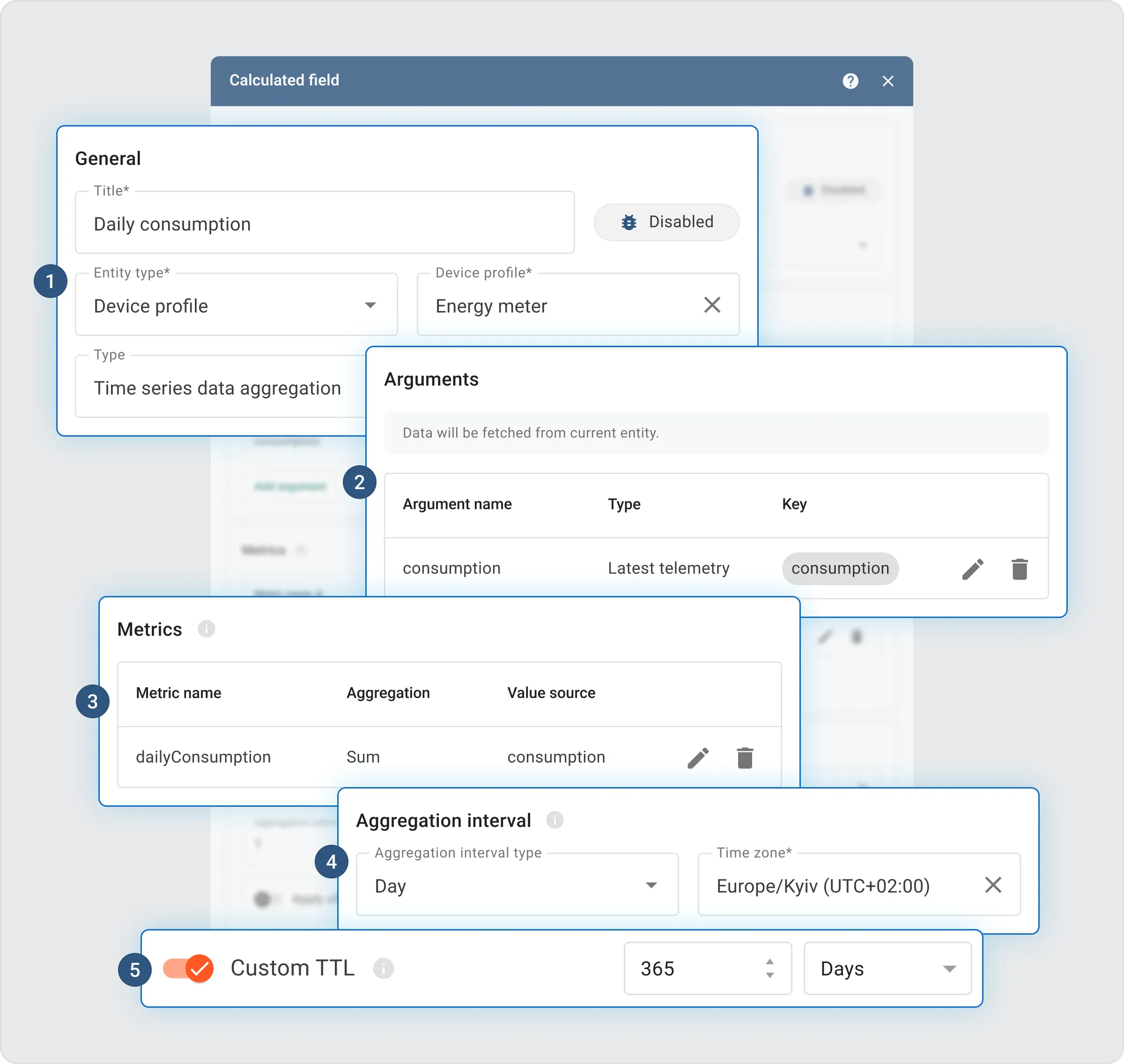
Practical approach: multi-level aggregation
- Daily aggregation (from raw telemetry): summarizes high-frequency raw data into daily metrics.
- Monthly aggregation (from daily telemetry): Calculates monthly totals using already aggregated daily values.
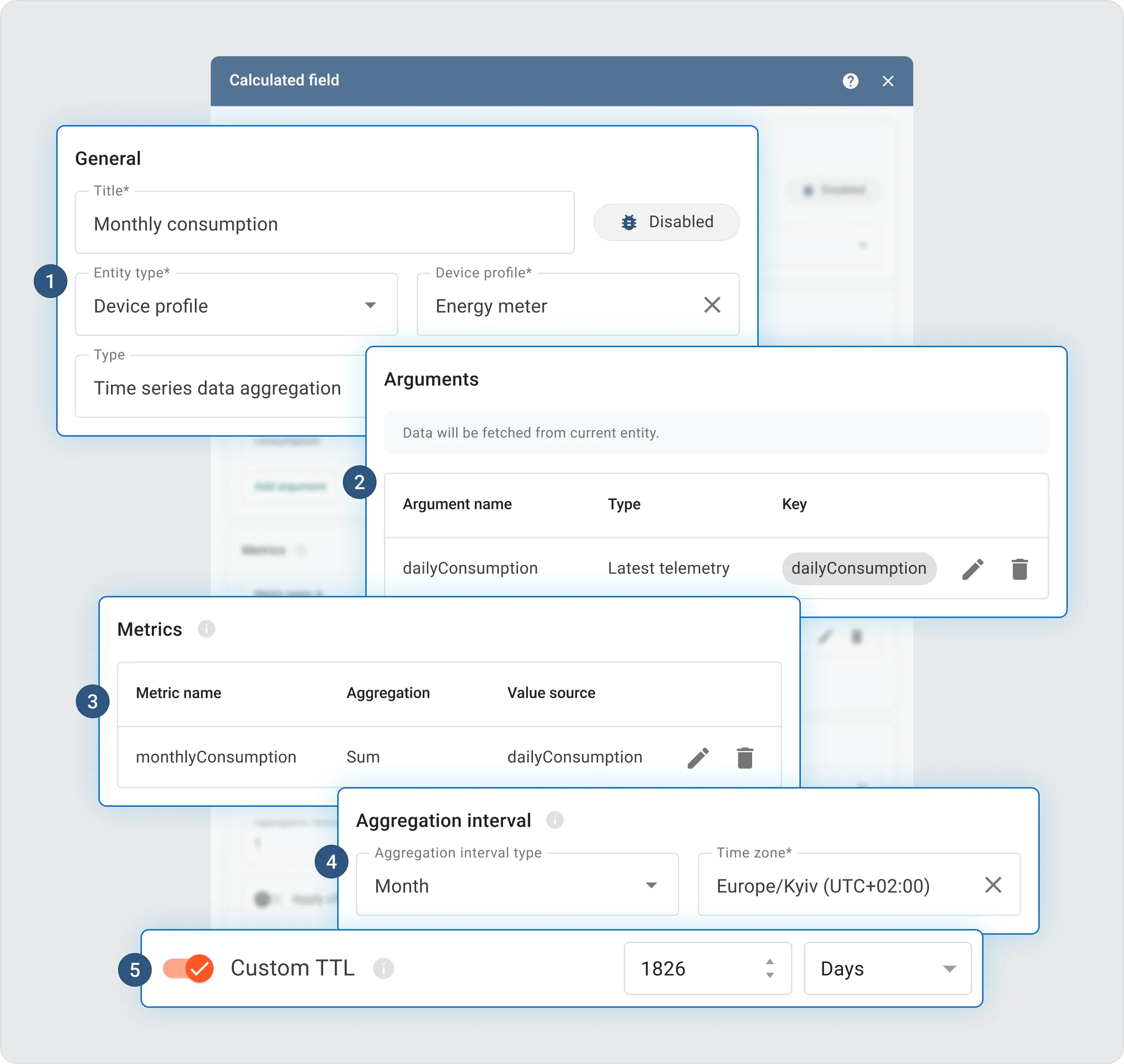
You may find the prepared calculated field JSON files for both aggregation levels below:
Step 2. Define retention rule for raw telemetry
While aggregated data is preserved for long-term use, the raw telemetry should only be kept as long as it is operationally useful. In ThingsBoard, this is configured by setting the Default TTL in the save time series rule node within your rule chain.
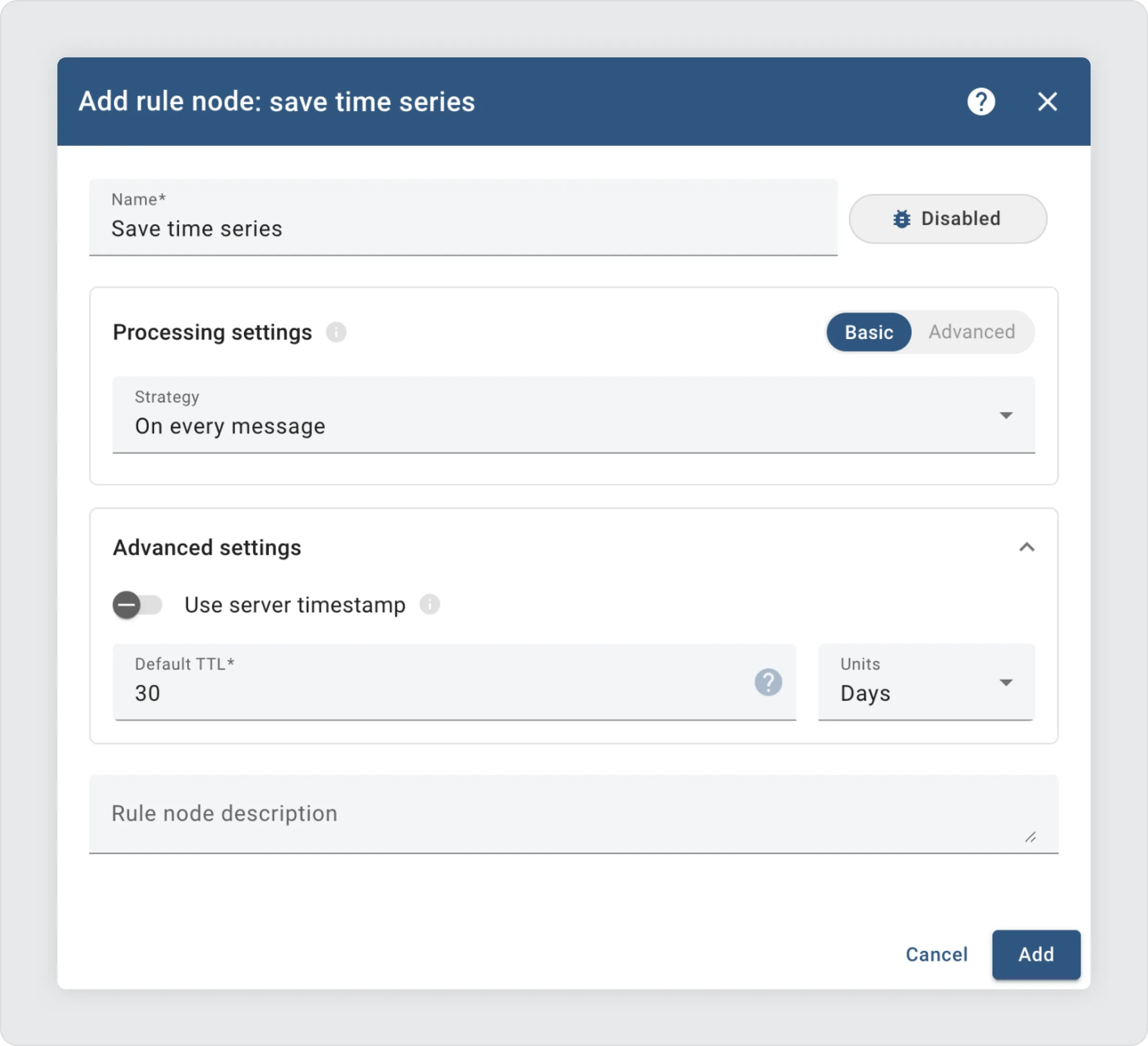
This ensures that detailed consumption measurements are automatically removed after it has served its short-term purpose, preventing unnecessary growth of storage.
Aggregated data TTLs are set per calculated field (Step 1) and are independent of the raw telemetry TTL.
Resulting data volume
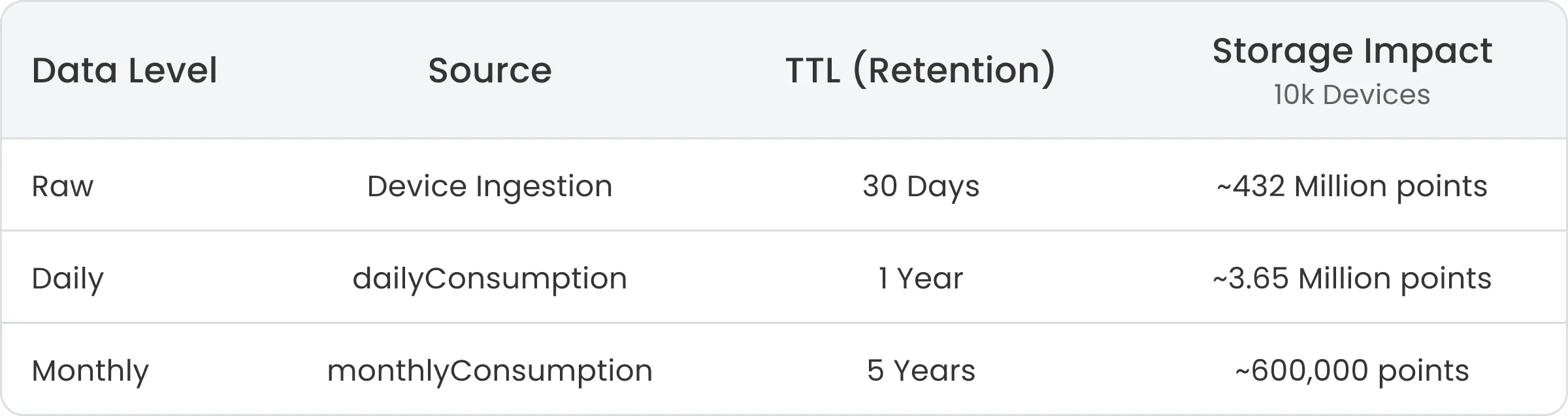
Compared to storing raw telemetry for 5 years (~26 billion points), this approach reduces long-term data volume by more than 50 times.
By pre-calculating these metrics during ingestion, long-term dashboards load almost instantly because the system retrieves ready-to-use summaries instead of performing expensive aggregations on millions of raw data points on request.
Best Practices
To get the most value from aggregation and controlled data retention in ThingsBoard, consider the following best practices:
- Align aggregation with analysis needs: Select aggregation intervals that match how the data will be analyzed. Use hourly aggregation for operational trends and daily or monthly aggregation for long-term trend analysis.
- Always define TTL explicitly: Avoid relying on defaults. Explicit TTL settings ensure predictable data lifecycle management.
- Limit raw telemetry retention: Keep high-frequency raw data for diagnostics and investigation, but avoid retaining it longer than required for operational needs.
Summary
By aggregating telemetry into time-based metrics and applying explicit retention rules, you enable efficient, scalable telemetry storage. Raw telemetry remains available for short-term operational needs, while aggregated telemetry supports long-term trend analysis, dashboards, and reporting.
This approach keeps storage growth predictable and significantly reduces long-term storage costs as your solution scales.